Redis 设计与实现读书笔记——第四章 字典
Redis 设计与实现读书笔记——第四章 字典
字典在Redis中应用很广泛,Redis的数据库就是用字典作为底层实现的,对数据库的增删改查操作也是构建在对字典的操作之上的。
简介
作用:
- 数据库底层实现
- 哈希键底层实现
- 哈希键包含的键值对比较多,或者键值对中的元素都是比较长的字符串时,使用字典来实现。
- 其他功能
4.1 字典的实现
字典使用哈希表实现,一个哈希表里面可以有多个哈希表节点,一个哈希表节点就保存了字典中的一个键值对。(python的dict也是使用哈希表实现的)。
哈希的本质就是预留内存空间,将需要存储的元素计算索引值(通过哈希函数)来确定对应的存储位置。当需要访问的时候可以通过哈希函数直接获得对应的地址。(编译器将变量名与地址做了映射,变量名是地址的别名,哈希则是将键与地址做了映射(通过哈希函数),大大提高了访问的效率。访问任何元素都是O(1),感觉是两个层面的映射,有点相似的感觉)。
4.1.1 哈希表
Redis使用的哈希表由dict.h/dictht 结构定义。
1 | typedef struct dictht { |
typedef Oldname newname 所以这里是typedef struct dictht dictht 将struct dictht 取了个别名dictht。
dictEntry **table; 书上解释的是table是数组,但是最直接的说法是table是一个指向(指向dictEntry类型的指针)的指针,是指向指针的指针。
数组获得内存是连续的,而指针不是,所以书中说是table数组,应该是分配内存的时候给指针分配了连续的内存,但是代码没找到。
关于指针和数组的异同《C专家编程》一书有讲解(第四章、第九章、第十章)。
- 主要的不同:指针存放的是地址,所以需要经过两次取地址的内容。(取指针的地址中的数据(变量的地址),取变量地址的数据)。而数组是直接存储数组的首元素的数据,所以只用一次取地址中的数据
- 数组与指针相同
- 表达式中的数组名就是指针
- C语言把数组下标作为指针的偏移量。a是数组,a[6]就是首地址偏移6。b是指针,b[6]也是指针存储的地址向后偏移6.
- 作为函数参数的数组名等同于指针。只是把首地址传入给了参数,并没有把数组所有的内存区域都传入。所以传入数组,就是传入指针。
sizemask和哈希值一起决定一个键应该被放到table数组的那个索引上面。

4.1.2 哈希表节点
使用dictEntry结构体表示节点,每一个dictEntry结构都保存着一个键值对。
1 | typedef struct dictEntry { |
key指向键值对中的键,而v则保存键值对中的值,值可以是一个指针,或者uint64_t整数,或者有符号的int64_t整数,或者是double类型(double也占8byte无论32还是64位)。
union 是c中的共用体(联合体),和结构体非常类似。和结构体的区别是
- 结构体的各个成员会占用不同的内存,互相之间没有影响;而共用体的所有成员占用同一段内存,修改一个成员会影响其余所有成员。
- 结构体占用的内存大于等于所有成员占用的内存的总和(成员之间可能会存在缝隙),共用体占用的内存等于最长的成员占用的内存。共用体使用了内存覆盖技术,同一时刻只能保存一个成员的值,如果对新的成员赋值,就会把原来成员的值覆盖掉。 所以这里面v占用8byte内存,但是属性却可以有4中。
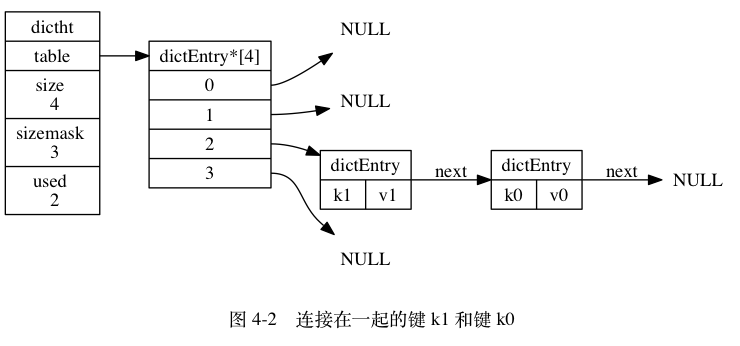
next指针可以将多个哈希值相同的键值对链接在一起,用来解决哈希键冲突(索引相同)的问题。链式的方法。
4.1.3 字典
Redis中字典由dict.h/dict 结构体表示。
1 | typedef struct dict { |
type 和private属性是针对不同类型的键值对(redis支持5中数据类型),为创建多态字典而设置的。
- type指向dictType结构,dictType结构保存了一簇用于操作特定类型键值对的函数,Redis为不同用途的字典设置了不同的类型的特定函数。(多态的表现。)
- privadata属性保存了需要传给哪些类型特点函数的可选参数。
1 | typedef struct dictType { |
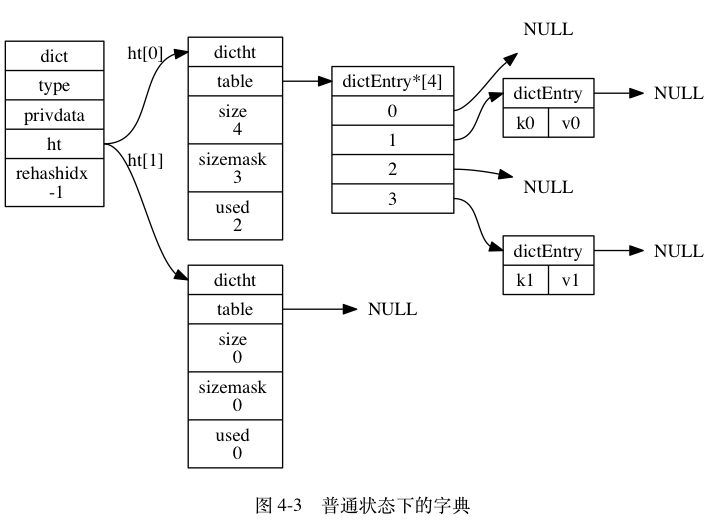
ht是长度为2的数组,而数组的元素就是哈希表dictht。一般情况只会使用ht[0],ht[1]只会在ht[0]空间不够的时候进行rehash的时候使用。
rehashidx 用来标识是否在 rehash,没有的话值为-1,有的话rehasidx用来记录rehash的进度。
4.2 哈希算法
添加一个新的键值对的时候,
1. 需要先根据键值使用hash函数计算哈希值
2. 哈希值和sizemask并运算求得索引值
3. 再根据索引值将包含键值对的哈希表节点放到哈希表数组table上的对应索引值上。
Redis 计算哈希值和索引值的方法为
1 | # 使用字典设置的哈希函数,计算键 key 的哈希值 |
哈希值用hashFunction计算,index用hash值和sizemask进行并操作。
对应在源码中为:
1 | //dict.h 中: |
插入一个键值对

先使用语句
1 | hash = dict->type->hashFunction(k0); |
计算键 k0 的哈希值。
假设计算得出的哈希值为 8 , 那么程序会继续使用语句
1 | index = hash & dict->ht[0].sizemask = 8 & 3 = 0; |
计算出键 k0 的索引值 0 , 这表示包含键值对 k0 和 v0 的节点应该被放置到哈希表数组的索引 0 位置上。

当字典被用作数据库的底层实现, 或者哈希键的底层实现时, Redis 使用 MurmurHash2 算法来计算键的哈希值。算法的优点
- 即使输入的键是有规律的, 算法仍能给出一个很好的随机分布性, 并且算法的计算速度也非常快。
MurmurHash 算法目前的最新版本为 MurmurHash3 , 而 Redis 使用的是 MurmurHash2 , 关于 MurmurHash 算法的更多信息可以参考该算法的主页: http://code.google.com/p/smhasher/ 。
暂时没有找到hashFunction的源码。
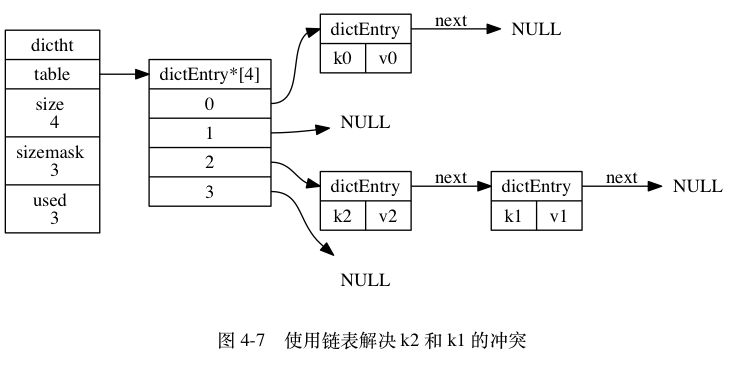
4.3 键冲突
两个以上的键分配到了同一个索引就产生了冲突。
使用链地址法解决,相同索引上面的节点可以用next指针来链接,这样同一个索引就可以存放多个哈希表节点了。
哈希表节点没有指向链表链尾的节点,所以不能迅速的知道哪个节点是尾节点,(只能通过遍历才能找到指向null的尾节点O(N)),所以为了速度考虑总是将新节点插入到最前面(dictht->table指针指向的第一个节点就是最前面的节点。)
直接使用书上的图:
还未发生键冲突

键冲突发生后:新键值对
4.4 rehash
哈希表保存的键值对会增多或者减少,需要让负载因子(负载因子(load factor),它用来衡量哈希表的 空/满 程度,一定程度上也可以体现查询的效率)维持在合理的范围,所以哈希节点太多的时候需要扩容(不然冲突太多,降低效率),这些哈希表的空间动态扩容或者缩容通过rehash操作来实现。
步骤为:
- 为ht[1]分配空间
- 扩容时ht[1].size = 大于等于ht[0].used*2的第一个2^n。
- 收缩时ht[1].size = 大于等于ht[0].used的第一个2^n。
- 迁移:将ht[0]上面的哈希节点重新计算哈希值与索引值并放到ht[1]哈希表上面。
- 迁移完成后释放ht[0],把ht[1]设置成ht[0],并在ht[1]新创建一个空白哈希表,等待下一次rehash。
注意:不管是扩容还是收缩,新分配的空间都会比原来用到的(used)大。设置ht[1]为ht[0] 的时候只需要简单的将原来ht[0]上面的指针指向ht[1]就好,但是需要把原来指向的哈希表的内存给释放掉。(指针是真的强,每次指针变换指向的地址的时候,都需要考虑下之前指向的地址是否还需要,不需要就要释放,不然会造成内存泄漏)。ht[1]则重新新建个哈希表结构体,然后把ht[1]的指针指过来就好了。
rehash的过程图解参考书中的图讲的很详细。

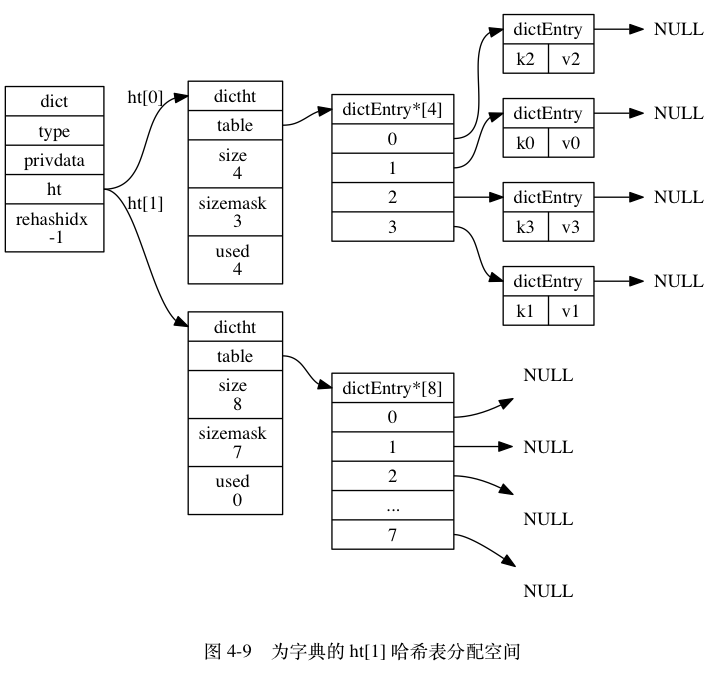
假设程序要对图 4-8 所示字典的 ht[0] 进行扩展操作。
ht[0].used当前的值为4,4 * 2 = 8, 而8(2^3)恰好是第一个大于等于4的2的n次方, 所以程序会将ht[1]哈希表的大小设置为8。图 4-9 展示了ht[1]在分配空间之后, 字典的样子:
- 将
ht[0]包含的四个键值对都 rehash 到ht[1], 如图 4-10 所示。
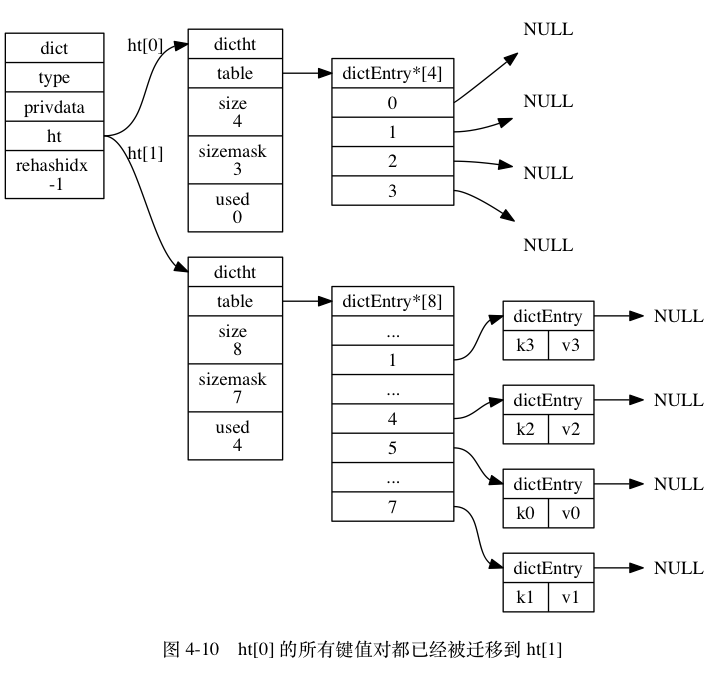
- 释放
ht[0],并将ht[1]设置为ht[0],然后为ht[1]分配一个空白哈希表,如图 4-11 所示。
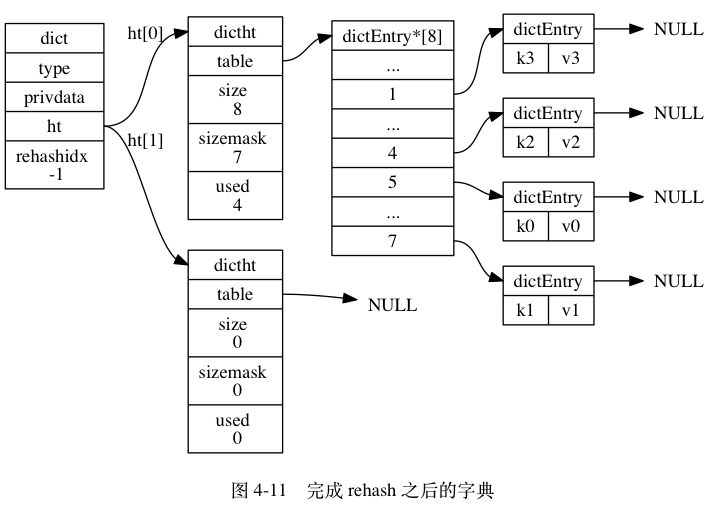
哈希表的扩展与收缩(源码还没找到)
当以下条件中的任意一个被满足时, 程序会自动开始对哈希表执行扩展操作:
- 服务器目前没有在执行 BGSAVE 命令或者 BGREWRITEAOF 命令, 并且哈希表的负载因子大于等于
1; - 服务器目前正在执行 BGSAVE 命令或者 BGREWRITEAOF 命令, 并且哈希表的负载因子大于等于
5;
其中哈希表的负载因子可以通过公式得到。
1 | # 负载因子 = 哈希表已保存节点数量 / 哈希表大小 |
4.5 渐进式rehash
考虑到redis数据库中存储的键值对很多的情况,如果一次性就rehash完,庞大的计算量可能会导致服务器性能急剧下降,甚至一段时间的停止服务,(经济学中的休克时疗法?)所以rehash这个过程需要渐进式的(软着陆)。
步骤:
- 为
ht[1]分配空间, 让字典同时持有ht[0]和ht[1]两个哈希表。 - 在dict中维持一个索引计数器变量
rehashidx, 并将它的值设置为0, 表示 rehash 工作正式开始。 - 在 rehash 进行期间, 每次对字典执行添加、删除、查找或者更新操作时, 程序除了执行指定的操作以外, 还会顺带将
ht[0]哈希表在rehashidx索引上的所有键值对 rehash 到ht[1], 当 rehash 工作完成之后, 程序将rehashidx属性的值增一。 - 随着字典操作的不断执行, 最终在某个时间点上,
ht[0]的所有键值对都会被 rehash 至ht[1], 这时程序将rehashidx属性的值设为-1, 表示 rehash 操作已完成。
注意:
- rehashidx的范围是从-1到ht[0].size-1 ,也就是对应的哈希表的索引,不是之前理解的记录哈希节点的个数。
- 迁移的过程不是拷贝,而是哈希表存储的哈希指针重新指向哈希节点的过程(指针对地址的操作)。
rehash 键值对所需的计算工作均滩到对字典的每个添加、删除、查找和更新操作上, 从而避免了集中式 rehash 而带来的庞大计算量。
过程图解依然copy自redis设计与实现的电子书。






渐进式rehash期间的哈希表操作
增删改查在两个表上操作,但是添加的新键只添加到ht[1]上,确保ht[0]最终变成空表。
4.6 字典API
疑惑
为什么不直接用
dictEntry *table[]来表示,却要用指针?应该是指针更加灵活些?- 因为dict有两个哈希表,而其中有个哈希表ht[1] 是只有在rehash的时候才会使用的,因此使用指针的的话,在不需要的时候将table直接指向null就可以简单的完成释放空间的操作,如果用数组的话,在分配内存的时候,就必须要为两个dictht都分配size个byte的内存存储空间,当rehash的时候size会变化,结构体中的数组就需要重新分配内存空间,而结构体的内存是相邻连续的,所以这时候要变化空间,只能重新再给这个结构体分配空间,这样效率肯定就很低了。所以使用指针的原因就是rehash的时候数组的大小会变化,如果用数组来记录就很麻烦和效率低了。
- 所以在dict中可以使用数组来存储dictht,因为ht这个数组是不会变化的。
既然在rehash过程中会有增删改查的操作,那么这些操作是在哪个哈希表上进行的呢?
- 两个哈希表上面都会进行,但是增加的键值对会在ht[1] 上,不然ht[0]在减少的时候又新增键值对,不是在做无用之功吗。
参考
http://redisbook.com/preview/dict/hash_algorithm.html
https://blog.csdn.net/yangbodong22011/article/details/78467583








