Redis源码阅读——SDS
Redis源码阅读——SDS
参考Redis设计与实现 以及网上博客阅读Redis源码。
SDS相关知识点见读书笔记。
创建和销毁
为了能够对sds进行相关API的测试,因此把sds模块单独提出来。阅读Redis的Makefile发现,编译sds模块需要的源文件包括sds.c, sds.h zmalloc.c
1 | test-sds: sds.c sds.h |
但是实际编译后会发现会报很多函数未定义的错。原因是redis源码里面sds的内存分配、释放、重分配这些函数是封装成zmalloc,zfee这些函数的,只单纯的把zmalloc.c提取出来是远远不够的。后面发现redis的作者已经把sds给单独提出来了。包括三个源文件sds.c,sds.h,sdsalloc.h 因此执行如下操作即可单独把redis的sds模块提取出来。
提取sds模块
新建redis_sds测试目录
选择合适的目录下新建
mkdir redis_sds复制源文件至redis_sds目录下
在redis源码的src目录下执行:
cp sds.c ~/redis_sds/cp sds.h ~/redis_sds/cp sdsalloc.h ~/redis_sds/修改sdsalloc.h
复制过来的sdsalloc.h 将sds模块的内存函数封装为使用zmalloc函数。为了简化处理直接使用libc的malloc函数来进行内存管理,同时将zmalloc.h给注释掉。
1
2
3
4//#include "zmalloc.h"
新建主函数
新建主函数sds_test.c
1
2
3
4
5
6
7
8
9
10
11
12
13
14
//#include "sds.h"
int main(int argc, char *argv[]) {
sds s = sdsnew("Hello World!");
printf("Length:%d, Type:%d\n", sdslen(s), sdsReqType(sdslen(s)));
s = sdscat(s, "The length of this sentence is greater than 32 bytes");
printf("Length:%d, Type:%d\n", sdslen(s), sdsReqType(sdslen(s)));
sdsfree(s);
return 0;
}直接include sds.c 即可,因为如果#include “sds.h” 的话,sdsReqType这个函数并没有在sds.h里面声明,而且因为sdsReqType的申明是:
static inline char sdsReqType(size_t string_size) {有static限制所以不能在sds.h中先声明,所以为了简单就直接#include 了sds.c了编译
为了方便重复编译,所以写了个简单的Makefile。
1
2test : sds_test.c sds.h sds.c sdsalloc.h
gcc -o sdstest sds_test.c只需要编译sds_test.c 即可。因为sds_test.c 里面是直接#include sds.c 了所以再
gcc -o sdstest sds_test.c sds.c会将sds.c 里面的函数重复编译两次,造成Multiple definition 问题。之后只需要执行make命令就可以生成可执行文件sdstest。
执行后输出为:
1
2
3./sdstest
Length:12, Type:0
Length:64, Type:1sds的创建
通过
sdsnew来创建了一个sds。sdsnew源码为:1
2
3
4
5
6/* Create a new sds string starting from a null terminated C string. */
sds sdsnew(const char *init) {
//使用?条件判断符来简化if语句对NULL的判断,直接使用strlen来返回字符指针的长度。
size_t initlen = (init == NULL) ? 0 : strlen(init);
return sdsnewlen(init, initlen);
}需要注意的是字符数组和字符指针是有区别的:字符指针的数据是存放在进程的虚拟地址空间的程序代码和数据段,是只读的不能修改。字符数组存放的字符串数据是存放在用户栈的,是可以更改的。且字符指针的数据没有”\0”这个结束符。
参考博客讲的很好:https://blog.csdn.net/on_1y/article/details/13030439
sdsnew通过把字符串长度和字符串传递给sdsnewlen,来完成创建。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
/* Create a new sds string with the content specified by the 'init' pointer
* and 'initlen'.
* If NULL is used for 'init' the string is initialized with zero bytes.
*
* The string is always null-termined (all the sds strings are, always) so
* even if you create an sds string with:
*
* mystring = n("abc",3);
*
* You can print the string with printf() as there is an implicit \0 at the
* end of the string. However the string is binary safe and can contain
* \0 characters in the middle, as the length is stored in the sds header. */
sds sdsnewlen(const void *init, size_t initlen) {
void *sh;
sds s;
char type = sdsReqType(initlen); //返回字符串对应的type
/* Empty strings are usually created in order to append. Use type 8
* since type 5 is not good at this. */
/*
空字符串使用sdshdr8来存储,而不是sdshdr5,(虽然长度小于32),因为sdshdr5不适合扩容。
*/
if (type == SDS_TYPE_5 && initlen == 0) type = SDS_TYPE_8;
int hdrlen = sdsHdrSize(type); // 返回对应类型的sdsheader长度。
unsigned char *fp; /* flags pointer. */
sh = s_malloc(hdrlen+initlen+1); // 申请头部+字符串+NULL的大小。(单位为byte)
if (!init)
memset(sh, 0, hdrlen+initlen+1); // 将sh后面对应大小的字节全部置为0;
if (sh == NULL) return NULL;
s = (char*)sh+hdrlen; //s指针指向字符串的首字节。
fp = ((unsigned char*)s)-1; // fp指针指向flag
switch(type) { // 初始化sdshdr
case SDS_TYPE_5: {
*fp = type | (initlen << SDS_TYPE_BITS);// 设置flag这个字节的具体值
break;
}
case SDS_TYPE_8: {
SDS_HDR_VAR(8,s); // 获取header指针sh
sh->len = initlen; //header中len的初始
sh->alloc = initlen; //header 中alloc的初试
*fp = type; //flag 的初始。
break;
}
case SDS_TYPE_16: {
SDS_HDR_VAR(16,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_32: {
SDS_HDR_VAR(32,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
case SDS_TYPE_64: {
SDS_HDR_VAR(64,s);
sh->len = initlen;
sh->alloc = initlen;
*fp = type;
break;
}
}
if (initlen && init)
memcpy(s, init, initlen); // 将字符串拷贝到s(也就是buf数组)
s[initlen] = '\0'; //在字符串后面添加终止符
return s;
}char type = sdsReqType(initlen);获取sds类型,源码分析在读书笔记里面有记录。源码为1
2
3
4
5
6
7
8
9
10
11
12
13static inline char sdsReqType(size_t string_size) {
if (string_size < 1<<5) // string_size < 2^5
return SDS_TYPE_5;
if (string_size < 1<<8) //string_size < 2^8
return SDS_TYPE_8;
if (string_size < 1<<16) //string_size < 2^16
return SDS_TYPE_16;
if (string_size < 1ll<<32) //string_size < 2^32
return SDS_TYPE_32;
return SDS_TYPE_64;
}采用左移来计算对应多少位的范围,而不是用2^5 这样的乘法。直接移位比使用幂来计算快很多。
1<<5计算出来就是2^5 次方。1是int型,4byte32位。最低8bit位的二进制为:00000001 左移5位后变成了:00100000 对应的十进制既是32。计算n个bit位的最大值:(1<<n) -1
但是需要注意位数不够的情况。因为1是int型,只有32个bit。所以在左移32个bit时,需要使用long long int型。用1ll来表示,此时1ll为64个bit。
还得考虑机器是否为64位机器,在32位机器上LONG_MAX = 2147483647L,64位机器上LONG_MAX = 9223372036854775807L 。不论32位机器还是64位机器上 LLONG_MAX 都是9223372036854775807L 。所以当LONG_MAX == LLONG_MAX 说明字长为64bit。加上条件编译,说明在32位机器上不使用sdshdr32而直接跳到了sdshdr64,仅仅在64位机器上使用sdshdr32。原因是什么?还没想通
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15static inline int sdsHdrSize(char type) {
switch(type&SDS_TYPE_MASK) {
case SDS_TYPE_5:
return sizeof(struct sdshdr5);
case SDS_TYPE_8:
return sizeof(struct sdshdr8);
case SDS_TYPE_16:
return sizeof(struct sdshdr16);
case SDS_TYPE_32:
return sizeof(struct sdshdr32);
case SDS_TYPE_64:
return sizeof(struct sdshdr64);
}
return 0;
}因为struct里面的buf数组是柔性数组,计算结构体的大小的时候不会计算在内。
memset(sh, 0, hdrlen+initlen+1);memset函数会将sh中当前位置后面的hdrlen+initlen+1个字节全部置于0。 注意sh指向的是hdrlen+initlen+1个字节的首个字节。(sh指针存储的地址就是首个字节的地址。)memset源码为:https://github.com/gcc-mirror/gcc/blob/master/libgcc/memset.c
1
2
3
4
5
6
7
8
9
10
11/* Public domain. */
void *
memset (void *dest, int val, size_t len)
{
unsigned char *ptr = dest; // 用char来限定每次指针+1只移动一个字节。
while (len-- > 0)
*ptr++ = val;
return dest;
}假设
hdrlen+initlen+1为8 ,经过memset后,从sh首字节开始共有8个字节都被置为0。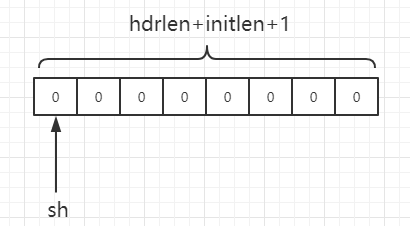
指针的类型时用来确定指针需要从首地址寻址(偏移)多少个字节。比如int * 指针说明指针存储的地址朝后面偏移3个字节才是这个int类型的所有数据。即指针存储的地址时起点,而终点是由类型来确定的。此外,类型也是指针加减的步长,比如char类型的步长就是1byte,而uint_16类型的指针步长就是2byte。
随后用switch语句对不同类型的sdshdr设置初始值。
首先是sdshdr5
*fp = type | (initlen << SDS_TYPE_BITS)使用移位和或操作的方式来对8个bit位赋值。(不得不感慨这些操作真的是太巧妙了)假设initlen为3。则initlen的二进制为0000 0011(应该是8byte(64位机器)或者4byte(32位机器),为了简单用1byte的二进制表示)而SDS_TYPE_BITS 为3。所以先将initlen 左移3个bit 变成0000 0001 1000(共有8byte或者4byte)。再与type进行或运算。type为0000 0000 进行或运算后,得到的内容是8bit的,因为type是char类型,即0001 1000 。
其他sdshdr类型的设置都差不多,详解下sdshdr8.
SDS_HDR_VAR(8,s)SDS_HDR_VAR是个宏定义的函数#define SDS_HDR_VAR(T,s) struct sdshdr##T *sh = (void*)((s)-(sizeof(struct sdshdr##T)));采用宏定义函数的好处是
- 能够减少额外的开销 因为如果写成普通函数的话,函数的调用会在用户栈开辟空间,形参压栈,返回时还需要释放栈,可想而知的开销。使用宏定义函数则在代码规模和速度方面都比函数更胜一筹。宏定义的本质就是替换,所以在使用宏定义函数的地方,执行的时候相当于是在直接执行
struct sdshdr##T *sh = (void*)((s)-(sizeof(struct sdshdr##T)))这句代码 - 函数的参数必须被声明为一种特定的类型,所以它只能在类型合适的表达式上使用。而宏定义则可以用于整形、长整形、单浮点型、双浮点型以及其他任何可以用“>”操作符比较值大小的类型,也就是说,宏是与类型无关的。(有点C++模版类的感觉)
宏定义函数中的## 是(token-pasting)符号连接操作符 直接将形参T链接到sdshdr上面。也就是sdshdrT。
所以这句代码也就很简单了,将字符串指针s向后移动header的大小,也就得到了header的指针。(不过有个疑问是为什么还要重新获取headr的地址,最开始不就是指向了header吗?,难道memset是直接对sh进行操作的?测试过了,memset不会修改sh的地址,所以应该是为了再次确保sh一定指向header)
解释一下:SDS_HDR_VAR 的作用是将sh的类型修改为结构体指针,因为之前sh 一直都是空指针,(虽然指针的指向地址是headr,但是没有限定它类型)不然后面没法用sh->len, sh->alloc 来访问对应的结构体成员。
最开始创建的时候alloc 和len是一样大的,没有分配多余空间)
memcpy(s, init, initlen);函数将init的前initlen个字符拷贝给s。memcpy源码为:
1
2
3
4
5
6
7
8
9
10
11
12/* Public domain. */
#include <stddef.h>
void *
memcpy (void *dest, const void *src, size_t len)
{
char *d = dest;
const char *s = src;
while (len--)
*d++ = *s++;
return dest;
}整个过程中的三个指针sh,s,fp对应关系如下图
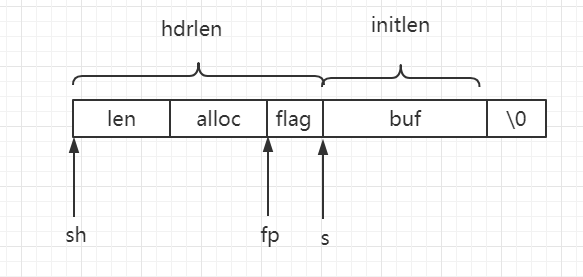
- 能够减少额外的开销 因为如果写成普通函数的话,函数的调用会在用户栈开辟空间,形参压栈,返回时还需要释放栈,可想而知的开销。使用宏定义函数则在代码规模和速度方面都比函数更胜一筹。宏定义的本质就是替换,所以在使用宏定义函数的地方,执行的时候相当于是在直接执行
销毁
销毁使用sdsfree来实现
源码为:
1 | /* Free an sds string. No operation is performed if 's' is NULL. */ |
s[-1],就是指针s向后移动移位,也就是flag的位置。将s移动到sh的位置,释放sh指针也就释放了整个sds内存。
疑惑:sh指针在sdsnewlen函数中是个局部变量,在sdsnewlen函数中是自动释放的,这里并没有传递sh指针为什么也可以释放对应的空间?
自己想了下:malloc 函数传递的参数是需要分配的内存大小(len),返回的是指针也就是地址。free()函数只用将malloc函数返回的指针(地址)作为参数传入,就可以释放之前该地址分配到的内存空间。而地址只是首地址,总共的偏移量(大小),应该是由操作系统在内存分配的时候就记录了的。
博客中记录:申请的时候实际上占用的内存要比申请的大。因为超出的空间是用来记录对这块内存的管理信息。额外的空间用来记录管理信息——分配块的长度,指向下一个分配块的指针等等。果然malloc的时候用来一个struct来记录分配的信息。
1 | struct mem_control_block { |
http://www.cnblogs.com/hanyonglu/archive/2011/04/28/2031271.html
free()就是根据这个结构体的信息来释放malloc()申请的空间
另外的疑惑:释放完空间后,s 指针不用把它指向null吗?
暂时就只是创建和销毁的源码把,看了两天,阅读源码真的是酣畅淋漓,收获良多。学到了很多奇妙的C技巧,还对操作系统的知识有了更具象的理解。
其他
阅读sdsfromlonglong部分的源码:
sdsfromlonglong 函数用于将一个long long 类型的整形数字转换为字符数组。
1 | /* Create an sds string from a long long value. It is much faster than: |
可以看到主要的转换操作在sdsll2str这个函数中:
1 | /* Helper for sdscatlonglong() doing the actual number -> string |
1 | do { |
假设v是352,变成字符串是将每一个对应的10进制上面的3,5,2这三个个位、十位、百位的数字给单独变成字符。
*p++ = '0'+(v%10); p 指针是字符数组buf的首地址,而将整型变成字符型的操作就是与字符’0’ 相加,这样就可以对应的数字变成字符类型。同时p相应的加1来指向下一个byte用来存储下一个被转换的char。
char类型存储的是对应字符的ascii值,ASCII表为:https://baike.baidu.com/item/ASCII/309296 ,所以字符的运算实际上是对应的ASCII的值的运算。
v%10是除以10取余数,352%10 =2; 35%10=5,所以也就是取得v值的10进制上面的个位数。
所以在while循环里面每次对v除以10并取余,就可以得到对应long long 型的字符串。
但是因为每次得到的字符都是最后面的个位数,所以352,所输出的字符串数组为:‘2’, ‘3’, ‘5’ 是一个倒序的,因此还需要再反转一次。
1 | /* Reverse the string. */ |
字符串反转,首尾各有一个指针,当首指针小于尾指针的时候,交换数字,并同时向中间移动
参考资料
https://blog.csdn.net/yangbodong22011/article/details/78419966









