数据仓库
数据仓库
什么是数据仓库
有多种定义,按照一位数据仓库系统构造方面的领衔设计师William H. Inmon的说法:数据仓库是一个面向主题的、集成的、时变的、非易失的数据集合,支持管理者的决策过程。
一句话总结:通过数据仓库来完成对一个项目的相关需求的快速分析,是一个联机分析处理(Online Analytical Processing System)系统,具体的定义见百度百科。
特征
- 面向主题的:数据仓库围绕一些主题,如顾客、供应商、产品和销售组织。数据仓库关注决策者的数据建模与分析,而不是构造组织机构的日常操作和事务处理。
- 集成的:通常,构造数据仓库是将多个异种数据源,如关系数据库、一般文件和联机事务处理记录,集成在一起。
- 时变的:数据存储从历史的角度(例如,过去5-10 年)提供信息。
- 非易失的:数据仓库总是。物理地分离存放数据;这些数据源于操作环境下的应用数据
操作数据库系统与数据仓库的区别
我们常见的关系数据库就是联机操作数据库,联机操作数据库系统的主要任务是执行联机事务和查询处理。这种系统称为联机事务处理(OLTP)系统。
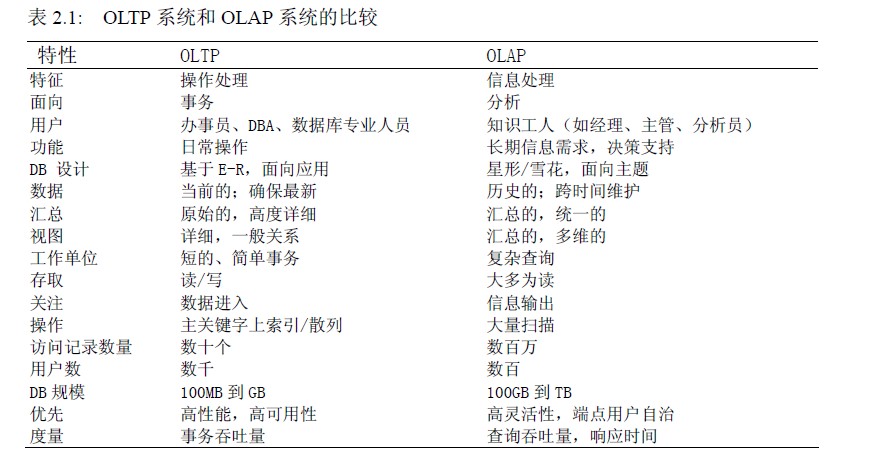
数据立方体
数据仓库基于多维数据模型,这种模型将数据看做数据立方体形式。
数据立方体的定义:在一个多维的平台上面对数据建模和观察,由维和事实定义。
每个维都可以有一个与之相关联的表,称作维表,在表中进一步的描述维更具体的属性(比如名字、类型等)。
多维数据模型围绕一个具体的主题(比如销售)这样的中心主题来组织。主题用事实表表示。事实是数值度量的,事实表包括事实的名称或度量。
一个具体的例子如下所示,表示的是关于销售这个事实的数据立方体。其中左边是一个二维的数据立方体,右边是一个三维的数据立方体。可以扩展到n维。以3d这个数据立方体,讲解下682这个值的含义,表示Toronto市,security项目在Q2季度的销售量。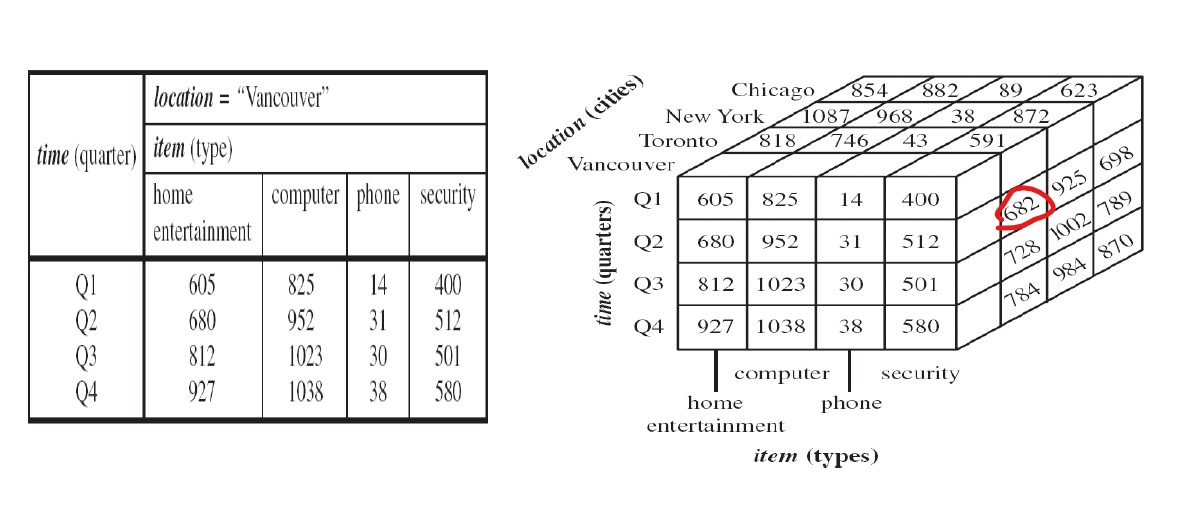
数据仓库建模
数据仓库最流行的数据模型是多维数据模型,这种模型有三种形式:星形模式(Star schema)、雪花模式(snowflake schema)、事实星座(fact constellation)
星形模式
最常见的模式,在这种模式下,数据仓库包括:
- 一个大的事实表,里面又包含
- 事实的维度
- 事实的度量
- 多组小的维表,详细记录一个维度的属性
例子如下,展开了很像星光四射,因而得名。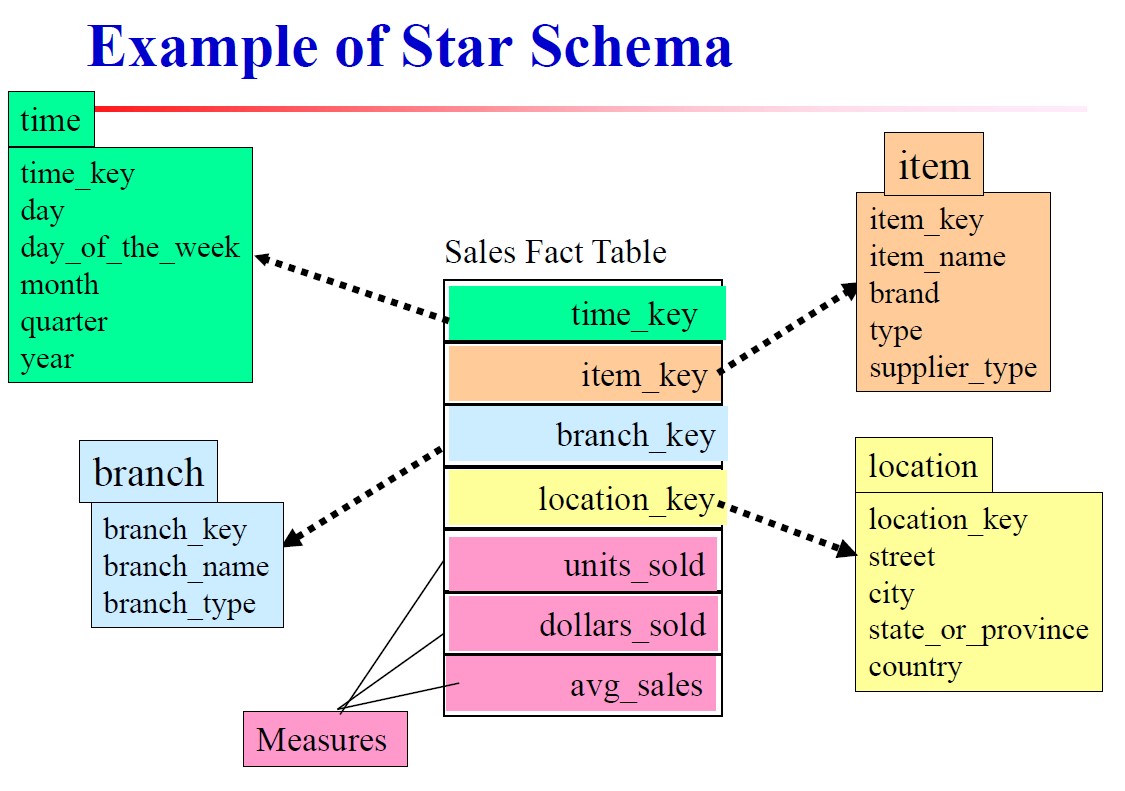
最中间的是销售事实表,总共有4个维度:时间、商品、部门(branch)、地点,3个度量:销售数量、销售金额、平均销售量。
雪花模式
雪花模式是星形模式的变种,其中某些维表被规范化,因而把数据进一步分解到附加的表中。
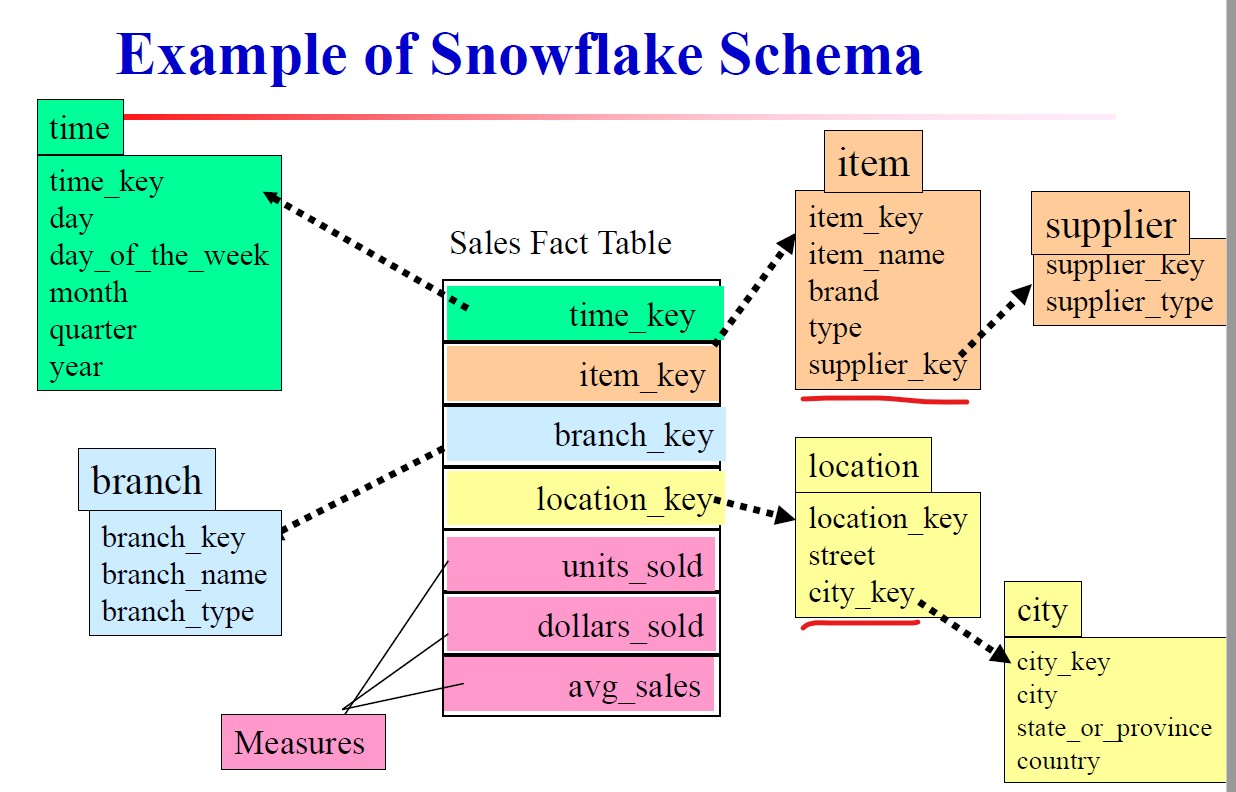
星形模式是只有一层的,而雪花模式可以延伸。图中在item维度又延伸出了供应商这个维度,在地点维度又延伸出了城市这个维度。
事实星座
对于一些复杂的应用可能需要多个事实表共享维表,这种模式可以看成星形模式的汇集,所以称做事实星座。
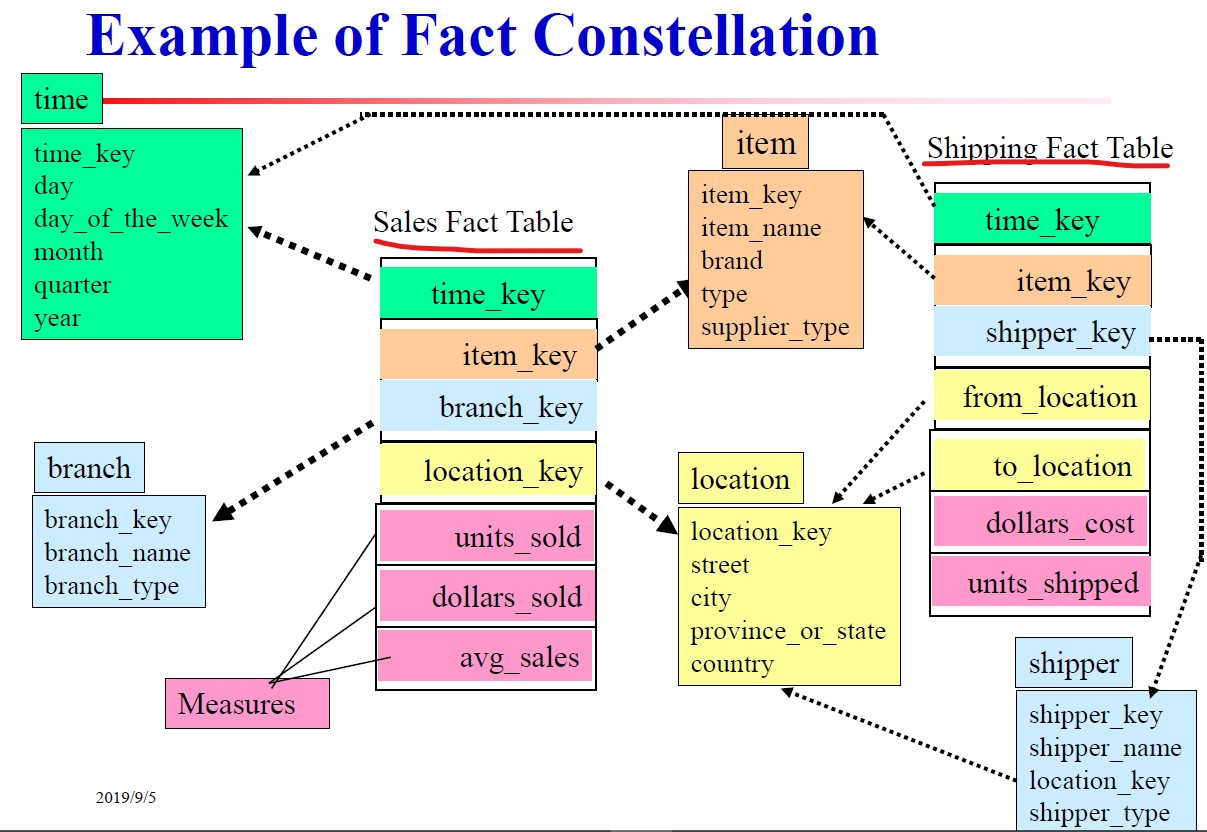
上面总共有两个事实表:销售与运输(Shipping)。因为两个事实表有些维度是共享的,所以同时指向相同的维度就可以了。
概念分层
概念分层(Concept Hierarchy),对一个维度在概念上进行分层。
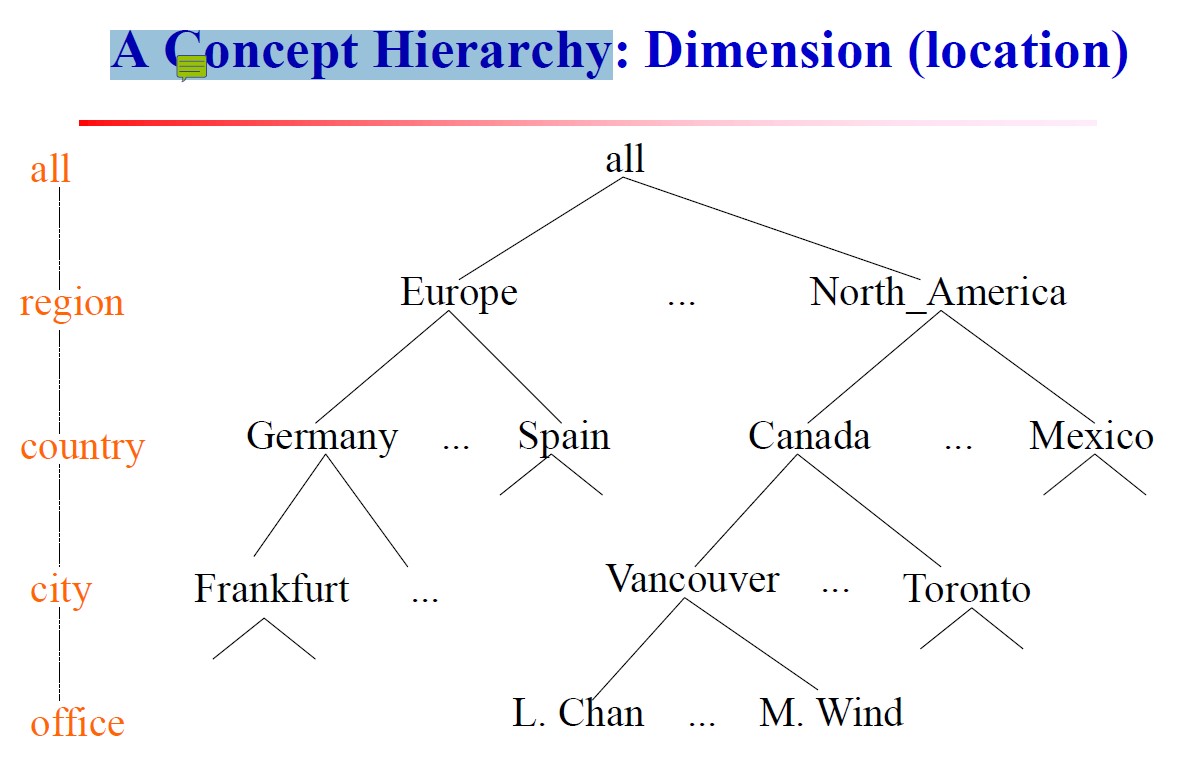
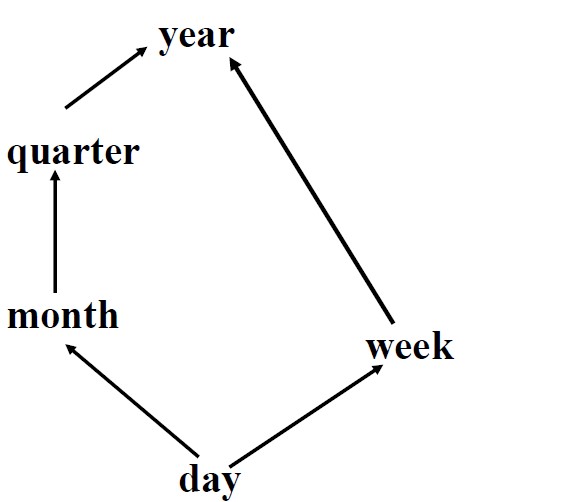
比如在地点上可以从办公室上升到城市上升到国家一直到最后的最高层所有。每个维度的最高层都是all所有这个级别。上图地点的分层是基于全序的层次结构,也可以组织成基于偏序的格结构,如下对时间的分层。
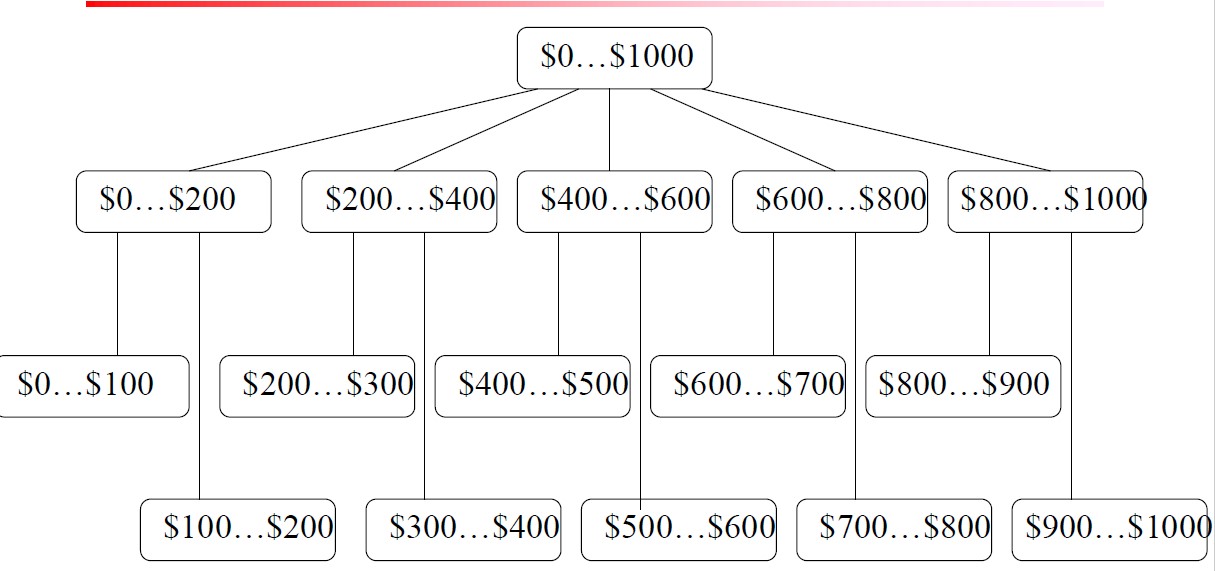
对于连续的属性值或或者维度,通过将其离散化来定义概念分层。
OLAP操作
进行实际分析的时候需要执行OLAP操作,典型的有下面四种。
上卷(roll-up)
上卷操作沿着一个维度的概念分层向上攀升。如下图所示的第1个操作,对location维度从城市上卷到国家,则原来的立方体的location维度从原来有4个城市变成只有两个国家。
下钻(drill-down)
下钻是上卷的逆操作,它由不太详细的数据到更详细的数据。
比如从第1个上卷的操作得到的数据立方体做从国家到城市的逆操作就回到了原来的数据立方体。第二个操作就是下钻操作,在time维度上从季度下钻到了月。
切片(slice)和切块(dice)
切片操作在给定的立方体上一个维度上面进行选择,形成一个新的子立方体。比如第3个操作,切边选择了time=Q1,因而得到的子立方体都是在Q1季度上的数据。
切块操作则是在多个维度上进行选择。比如第4个操作就是在location维度选择多伦多与温哥华,而在time维度上选择Q1与Q2季度,而在item维度上选择家庭娱乐与计算机。
转轴(pivot)
转轴又称作旋转(rotate),是一种目视操作,移动了数据的视角。比如第5个操作,将原来的item维度在下,location维度在上。旋转后变成了item维度在上,而location维度在下。类似于矩阵的转置。
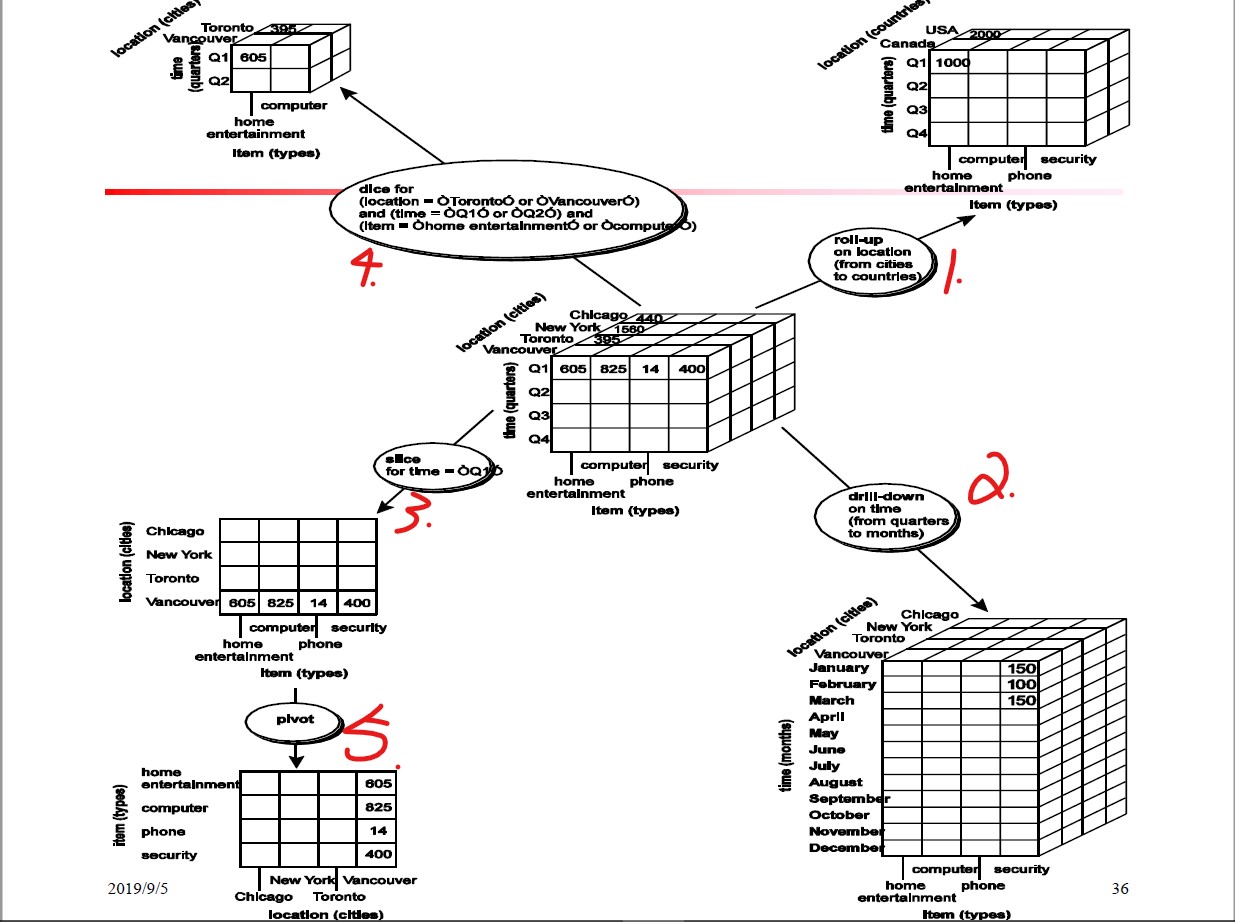
操作实例
Starting with the base cuboid [day, doctor, patient],what OLAP operations should be performed in order
to list the total fee collected by each doctor in 1999?
首先要求所有的费用,因此对patient维度做上卷操作,上卷到all所有这个层次。然后时间限定在了1999年,因此对day维度做上卷操作,上卷到年这个层次。最后进行切边操作,选择1999年这个年份。
数据仓库实现
数据立方体的有效计算
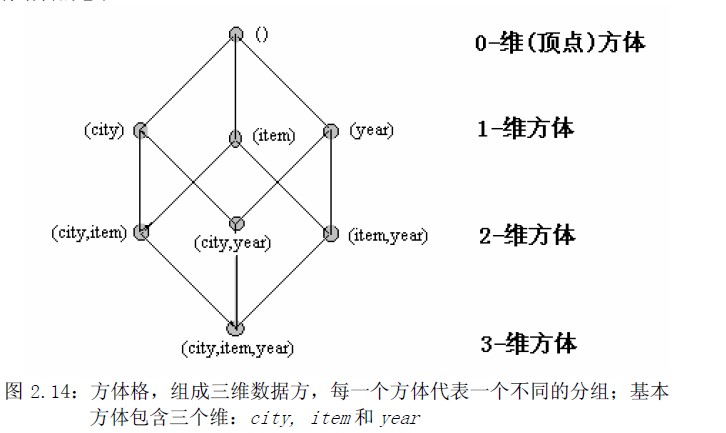
前述的OLAP操作依赖于对数据立方体的计算操作,既是针对不同维度上面的聚合,SQL的术语是分组(group-by)。对于n个维度的数据立方体,不考虑每个维度的概念分层,则总共可以构成的分组(不同维度组合的集合)有$2^n$种。如下所示,一个(city,item,year)的三维数据立方体可以有8种分组方式。
其实不考虑概念分层意味着每个维度可以有最高层all和最低层两个分层。因此如果考虑概念分层,假设有n个维度
,每个维度都有m个分层,则这样来说可有$m^n$个方体。
为了实现快速返回OLAP的操作,需要提前将这些分组的结果存储下来,这样当指定OLAP操作,直接去访问这些分组就可以了。这种提前计算方体结果的方法,称作物化(materialization)但是考虑到概念分层,存储所有的分组结果是不现实的。采用部分物化(partial materaialiaztion)预先计算一部分适当的常用的子集。
OLAP索引
位图索引(bitmap indexing)
在给定属性的位图索引中,属性域中的每个值v,有一个不同的位向量bit vector(即一列值)Bv。如果给定的属性域包含n 个值,则位图索引中每项需要n 位(即,n 位向量)。如果数据表中给定行的属性值为v,则在位图索引的对应行,表示该值的位为1,该行的其它位均为0。可以理解成one hot 编码。
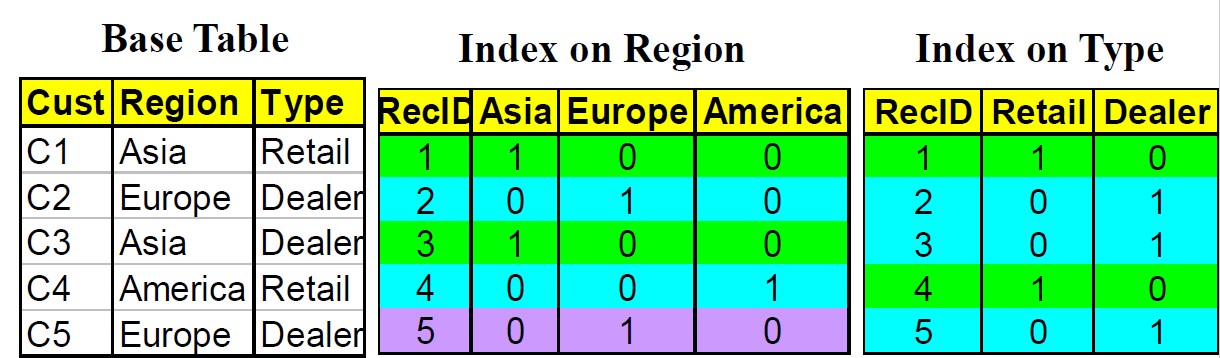
Region有3种取值,所以3个位向量,也就是对应3列值;Type有2种取值,所以对应2列值。
优缺点
优点:与散列和树索引相比,位图索引有优势。对于基数较小的域它特别有用,因为比较、连接、和聚集操作都变成了位算术运算,大大减少了运行时间。由于字符串可以用单个位表示,位图索引大大降低了空间和I/O 开销。对于基数较高的域,使用压缩技术,这种方法可以接受。但是不是很适合。
缺点:因为值域中的每一个可能的值都需要一个位向量来记录,所以当基数较大时,会需要开辟很大的存储空间,因为每一个记录其实只使用到了一位,因此造成了很大的浪费。同时当可取的值连续时无法使用位图来记录。
连接索引
如果两个关系R(RID,A)和S(B,SID)在属性A和B 上连接,则连接索引记录包含(RID,SID)对,其中RID 和SID 分别为来自R 和S 的记录标识符。
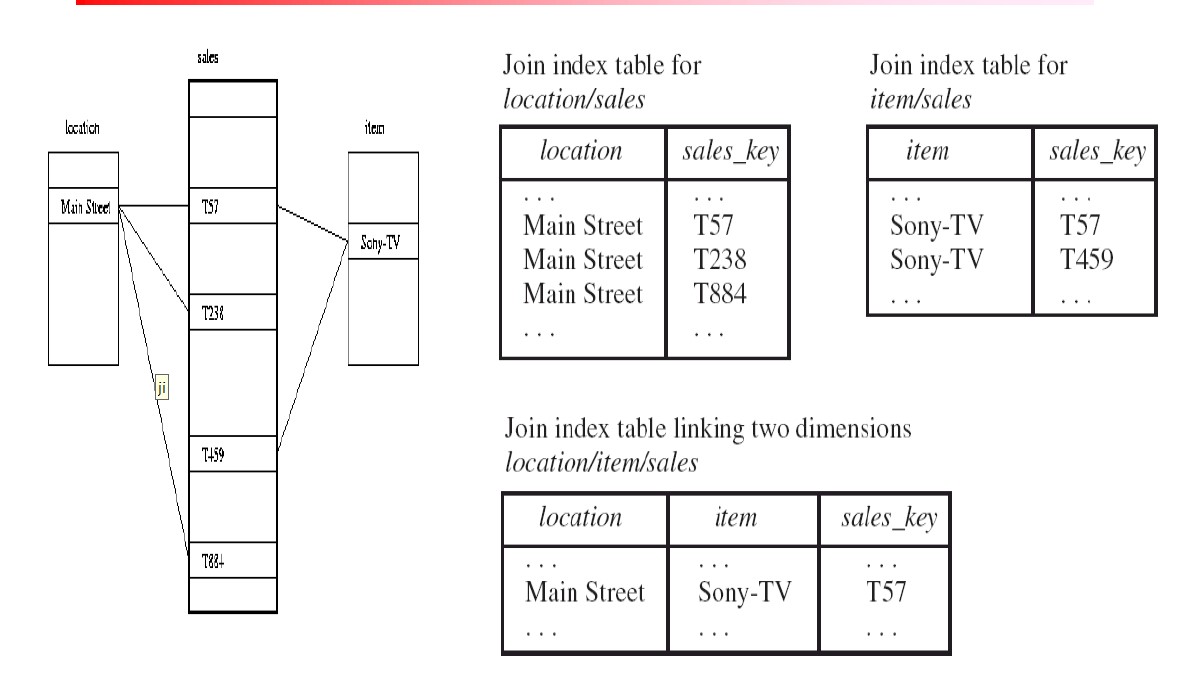
在左边的销售事实表中有同location和item两个维度的链接,那么就可以有右边3中连接索引。
参考
《数据挖掘概念与技术》第3版 第四章数据仓库与联机分析处理







