分类与预测
分类与预测
分类与预测的差别
分类对给定的数据集一般是离散的,确定这些数据对应类别。而预测是对连续的数据,根据历史数据来预测未知的数据或者缺失值等。
分类的过程分为两步:
模型构建
使用训练数据集对模型进行训练,模型可以被表示为一些分类的规则集合,决策树或者是数学公式。
模型使用
先使用模型来对测试数据进行分类,如果准确率能够接受则使用模型去对没有标注过的数据进行分类。
分类属于有监督学习,训练的数据是经过标注的。聚类属于无监督学习训练数据未经过标注不知道样本的标签。
在进行分类和预测之前需要对数据进行预处理包括数据清洗来处理噪声和缺失值,相关性分析来进行特征提取,数据转换比如归一化等。
对于分类方法的评测指标有:准确性,速度,鲁棒性,可规模性(硬盘数据),可解释性等
决策树
决策树是一个类似于流程图的树结构;其中,每个内部结点表示在一个属性上的测试,每个分枝代表一个测试输出,而每个树叶结点代表类或类分布。树的最顶层结点是根结点。给定数据经过决策树不同节点的决策最终走到叶子节点,从而完成了对数据的分类。决策树不需要任何领域知识也不需要参数,适合探测式知识发现。
决策数的构建分为两步:
- 树的构建 从根节点开始递归的选择属性进行建树
- 剪枝 :减去反映噪声或者离群点的分枝
构建决策树
算法伪代码为:

三个参数D是输入的数据集,attribute_list是输入数据中的属性集合和Atrribute_selection_method是指定选择属性的启发式过程,可以选择信息增益或者是基尼指数Gini index。
步骤为:
首先从根节点N开始,根节点中的数据是原始的需要分类的原始数据集。
如果D中的数据都属于同一类,那么根节点N变成叶子节点,标记为这一类。
否则,调用Atrribute_selection_method来选择最佳的分裂属性,并给出分裂子集。理想情况下希望分裂子集尽可能的纯,也就是希望分裂自己尽可能的都属于同一类。
用选出来的分裂属性在节点N上进行划分,并输出划分的数据子集。并把分裂属性从属性列表中删除。
- 选出来的属性是离散值的话,有多少个取值就产生多少个分支
- 连续值的话选择一个分裂值,大于这个分裂值为一个分支,小于等于为另外一个分支
- 离散值而且必须是二叉树的话:属于这个值为一个分支,否则为另外一个分支
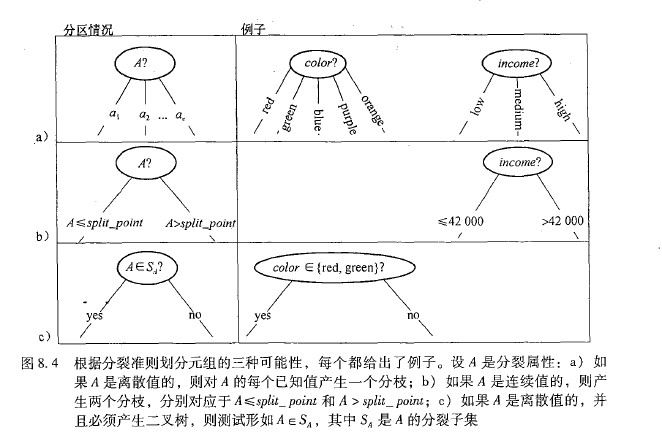
对于每一个删除了最佳分裂属性的输出的子集$D_j$ 递归的调用算法。
递归的终止条件:
- 数据集D都属于同一类
- 属性列表为空,使用数据集中的多数类来标记节点。(多数投票)
- 如果一个分支的数据$D_j$为空,则新增加一个叶子节点,用父节点数据集D中的多数类来标记它。
返回决策数的节点N
属性选择度量
很明显,决策树的关键点是怎么选择分裂的属性。有如下三种方式。
信息增益
ID3这种决策树方法使用。
先计算数据集D的熵:
假设数据集中D有m个类别${C_1,C_2\dots C_m}$,那么每一类的概率可以用所占的比例$p_i=\dfrac{count(C_i)}{count(D)}$来估计。
假设属性A 具有v 个不同值${a_1 ,…, a_v}$。可以用属性A 将S 划分为v 个子集${S_1 ,…, S_v}$;其中,
$S_j$ 包含S 中这样一些样本,它们在A 上具有值$a_j$。如果A 选作测试属性,则获得的信息增益,也就是划分成了子集后的熵为:
信息增益定义为原来的的信息需求(近基于类比例)与新的信息需求(对A划分后)之间的差:
具有最高信息增益的属性是最佳分裂属性。可以这样理解,划分后越纯那么整个状态越不混乱,也就是熵越低。所以选择划分后熵最低而信息增益最高的属性。
信息增益率
信息增益偏向有许多输出的测试,它倾向于选择具有大量值的属性。比如按照唯一的标识符id来划分,每个划分出来的都只包含一个数据都是纯的,但是这样的划分显然没有作用。
C4.5使用增益率来进行选择分裂属性。增益率用分裂信息值将信息增益归一化。
分裂信息值代表由训练数据集D根据属性A划分v个分区后,这v个分区的熵。前面的$Info_A(D)$是对每个分区还计算了一下分区里面的熵然后进行加权,而这里是全局地看待这v个分局而进行的计算。
增益率定义为:
选择具有最大增益率的属性作为分裂属性。
基尼指数
基尼指数在CART中使用,基尼指数度量数据集的不纯度,定义为:
$p_i=\dfrac{|C_i|}{|D|}$依然用每一类的比例来估计。基尼指数考虑每个属性的二元划分,根据属性A划分成两个两个子集$D_1,D_2$在这种划分下的基尼指数为:
选择具有最低的基尼指数作为分裂属性。
决策树决策规则
构建好了决策树后,决策规则使用IF-THEN的语句来表示。
比如上图的决策规则是:
1 | IF age is Middle_aged THEN buys_computer = yes |
有多少个叶子节点相应的有多少决策规则,在到达叶子节点的路径上有多少个节点就有多少个并列的条件。
过拟合与树剪枝
在创建决策树时,由于数据中的噪声和离群点,许多分支反映的是训练数据中的异常。使用剪枝的方法来处理这种过拟合的问题。
先剪枝
先剪枝prepruning方法提前停止树的创建。比如设定一个阈值当信息增益等度量超过阈值则分裂,不超过就停止分裂,用投票的方法确定标签。但是阈值的设置比较困难,所以不常用。
后剪枝
后剪枝postpruning方法从完全创建好了的决策树进行剪枝。剪去后也依然使用投票的方法来确定标签。
CART使用代价复杂度剪枝算法,C4.5使用悲观剪枝的方法。二者都是根据错误率,简单说就是如果减去这个分支后错误率提升不大就可以减去。
决策树评价
比其他的分类方法有着相对更快的学习速度,能够转换成容易理解的决策规则,准确率也能接受,而且也可以适用于大规模的数据。
贝叶斯分类
朴素贝叶斯分类发假定一个属性值在给定类上的影响独立于其他属性的值,这个假定称为类条件独立性。做这个假定是为了简化计算,因而称之为朴素的。
贝叶斯定理
贝叶斯定理用来求解后验概率。公式为:
X是数据样本,分类未知。H是对X的分类的假设,比如X属于C类。P(H)是猜测的类的概率,P(X)是观察到的样本X的概率,而P(H|X)是在给定H的假设下,观察到X样本的概率。
朴素贝叶斯分类
工作过程
训练数据集D中一个样本X向量用一个n维的列向量$[x_1,x_2\dots x_n]^T$来表示它对应的n个属性$[A_1,A_2\dots A_n]$的测量值。
假定有m个类$C_1,C_2\dots C_n$,将X预测为拥有最高后验概率的类。
因为$P(X)$是常数,所以只用最大化$P(X|C_i)P(C_i)$ $P(C_i)$用类的频率来估计
在类条件独立的假定下有:
$x_k$表示样本X向量对应的第k个属性$A_k$的值。
如果$A_k$是分类属性,那么$P(x_k|C_i)$是D中属性$A_k$的值为$x_k$的$C_i$类的元组数除以D中$C_i$的数目
如果$A_k$是连续值,则假定连续值服从均值为$\mu$,标准差为$\sigma$的高斯分布。
所以可以得到:
对每一类都分别计算$P(X|C_i)P(C_i)$ 最后选择最大的作为这个样本的分类。
零概率值的解决
在做连乘的时候如果有一个的概率为0,那么整个计算结果都为0。可以假设训练数据集很大,将每个取值的计数都加1而造成的概率估计可以忽略不计。这样就可以避免出现零概率的情况,称之为拉普拉斯估计或这拉普拉斯校准法
评价
朴素贝叶斯的优势:比较容易实现,在大多数情况可以取得好结果。缺点是:因为做了属性互相独立的假设,因此会降低准确率。而且实际上,大部分属性之间并不互相独立。
可以使用贝叶斯信念网络来处理。
BP神经网络
多层前馈神经网络
后向传播算法Back propagation在多层前馈神经网络上学习。由输入层、一个或多个隐藏层和一个输出层组成。

输入层的单元称作输入单元,隐藏层和输出层单元称作输出单元或者神经节点。输入向量输入进输入单元,然后加权同时地提供给隐藏层的输出单元。在全连接的情况下每一层单元与前后层单元都会有相应的权重,因为权重不会回馈到输入节点,所以称为前馈的。因此一次输入就完成输出。
网络拓扑的定义
应该设计多少层隐藏层,每一层有多少单元,输入层单元应该有多少,是否全连接等都是网络拓扑需要考虑的。
需要先对输入值进行归一化,将值落入[0,1]之间。离散值的属性可以进行重新编码,让每一个域值都有一个输入单元。如果属性A有3个可能的值${a_0, a_1, a_2}$那么就需要设计3个输入单元$I_0, I_1,I_2$,输入单元$I_1$为1对应属性$A=a_1$。
如果进行分类的话如果只有两类那么输出单元只用一个就可以了,多于2类的情况每一类都有一个输出单元。
隐藏层单元数目的设计,没有明确的规定,通过反复实验的过程,来确定。一般选择一个隐藏层就可以了,权重的初始值也会影响结果的准确率。
后向传播
步骤
后向传播通过迭代地处理训练数据,把每个样本的网络预测值与实际已知的目标值相比较。对每个训练样本,修改网络的权重使得网络预测和实际目标值之间的均方误差最小。修改后向进行,从输出层一直传递到输入层的,因此叫做后向传播。
算法伪代码为:

步骤为:
初始化权重:权重被初始化为小随机数(比如-1到1,或者-0.5到0.5),偏倚bias也初始化为小随机数。
向前传播输入:输入单元的输出就是输入值。隐藏层和输出层单元的净输入用上一层输入的线性组合计算。输出单元的输出用激活函数计算,激活函数是logistic或这S型sigmoid函数,激活函数将较大的输入值域映射到区间[0,1]
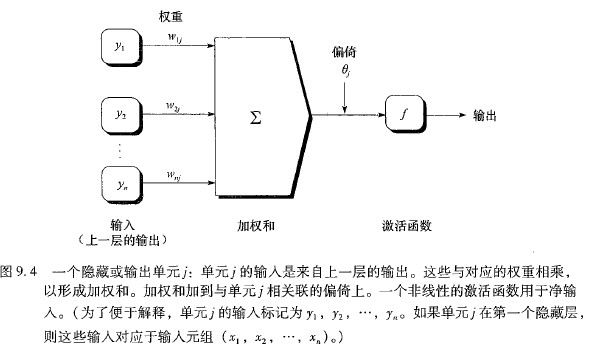
隐藏层或者输出层单元j其输入为如下,其中$w_{ij}$是上层单元i到单元j的权重,$O_i$是上一层单元的输出,$\theta_j$是单元j的偏倚。偏倚用来充当阈值,改变单元的活性
单元j的输出$O_j$为:
向后传播误差:通过更新权重和反映网络预测误差的偏倚,向后传播误差。对于输出层单元j,误差如下,其中$O_j$ 是单元j的实际输出, $T_j$ 是j给定训练样本的实际目标值,$O_j(1-O_j)$是逻辑斯提函数的导数。
隐藏层单元j的误差,考虑下一层中j连接的单元的误差加权和。误差如下:
其中$w_{jk}$是下一层单元k与单元j的连接权重,而$Err_k$是单元k的误差。
更新权重和偏倚,以反映误差的传播。权重更新公式如下,其中$\Delta w_{ij}$是权重的改变量。
变量l是学习率,通常去[0,1]之间的常数值。学习率帮助避免陷入决策空间的局部极小,并有助于找到全局最小。学习率太低的话,学习将进行的很慢。学习率太高的话,可能出现在不适当的解之间的摆动。一种调整规则是将学习率设置为迭代次数的倒数。
偏倚的更新公式为:其中$\Delta \theta_{ij}$是偏倚的改变量。
更新的策略有实例更新:每处理一个样本就更新权重和偏倚。周期更新为处理玩所有样本后再更新。实例更新通常产生更准确的结果。
终止条件:
- 前一周期所有的$\Delta w_{ij}$都太小,小于某个阈值
- 前一周其误分类的数据百分比小于某个阈值
- 超过预先指定的周期数。实践中权重收敛可能需要数十万个周期。
和决策树一样,神经网络也可以剪枝,去除那些影响很小的连接。
优缺点
优点:
- 对噪声的高容忍
- 对连续值的良好适配
- 对真实数据的良好处理
- 效果很好
缺点:
- 很长的训练时间
- 要求大量的参数
- 解释性很差
其他分类方法
包括KNN、集成学习比如(Baggin、Boosting)
预测
线性回归模型、多项式回归模型、广义线性模型、对数线性模型(针对分类数据)
准确率和误差的衡量
使用混淆矩阵confusion matrix来表示分类的情况。
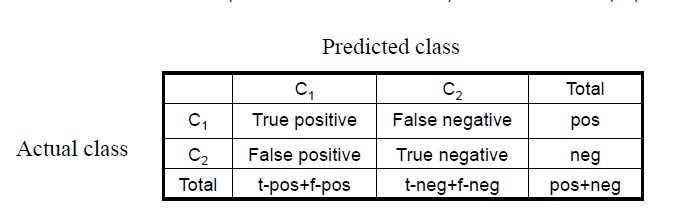
准确率和错误率表示为:
还有其他几个指标
参考
《数据挖掘概念与技术》第3版 第八章分类:基本概念 第九章 分类高级方法








