ICPP 2018 ImageNet Training in Minutes
来源
关键词
分布式机器学习,神经网络加速
摘要
文章对大规模计算机的DNN加速能力进行了研究。通过使用LARS算法提供的Large batch来充分利用海量的计算资源,该方法在ImageNet-1k数据集上训练出的AlexNet和ResNet-50这两个网络达到了SOTA的精读。和Facebook以往提出的Baseline相比,该方法在batch size超过16k上有着更高的精度。使用2,048 Intel Xeon Platinum 8160处理器将100 epoch的AlexNext的训练时间从几小时下降到了11分钟,使用2,048 Intel Xeon Phi 7250处理器将90 epoch的训练时间从几小时下降到了20分钟。
结论
大意同摘要,文中讨论了大规模计算机来加速的优点与困难。
引言
问题1:对于深度学习应用,更大的数据集和更复杂的模型带来了准确率的显著提高,随之而来的是更长的训练时间。
思路1:如果把神经网络的训练使用超级计算机来实现,短时间完成。
同步SGD算法在目前取得了最好的效果,将batch size提高可以更好的利用机器。每个处理器处理更多的样本。增加处理器与batch size 来减少训练时间,但是large batch会带来测试准确率的下降。使用warm up和linear scaling rule 方法来扩大batch size 并减少训练时间。使用Layer-wise Adaptive Rate Scaling (LARS)可以扩大到32k。
本文的出发点:使用LARS算法可以在ImageNet-1k上面将DNN的batch size扩大到多少?
本文贡献:
- 使用LARS,扩展到上千个CPU上训练DNN网络。
- 检验了LARS在AlexNet和ResNet-50上的通用性。
- LARS在32k的batch size上展现了更好的鲁棒性
- 工作已经开源
其他相关工作:数据并行的SGD和模型并行的两种分布式并行DNN训练方法
方法
关注数据平行的随机梯度下降方法SGD。因此通信开销与模型的复杂度(参数的数量)成比例。
大批量large batch 不改变总的计算量,但是会减少通信的开销。
模型选择了AlexNet and ResNet-50作为代表,因为二者有不同scaling ratio,ResNet-50更高的scaling ratio因此比AlexNet更容易扩大batch size
目标:在测试准确率不降低的前提下来增大batch size
保持准确率的现有的方法:
- Linear Scaling:学习率同batch size一样线性增长
- Warmup scheme:在前几代中从小学习率逐渐增长到大学习率
本文使用的方法LARS+warmup算法:不同层需要使用不同的学习率,标准的SGD是所有层都一样的。调整的方式就是LARS:
$l$是scaling 因子,$\gamma$是可调参数。
LARS方法流程:
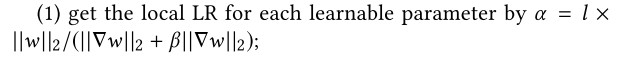

结果
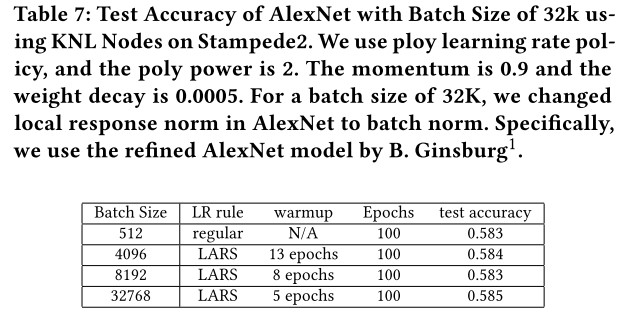
使用LARS方法与warmup在AlexNet上的测试精度
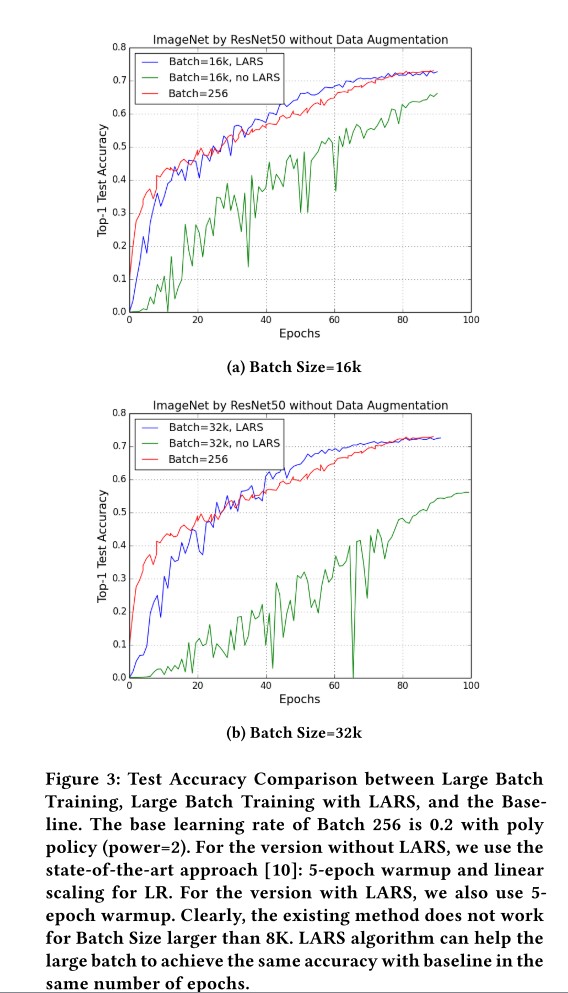
ResNet50 在ImageNet上面才用不同16k和32kbatch size 的结果。
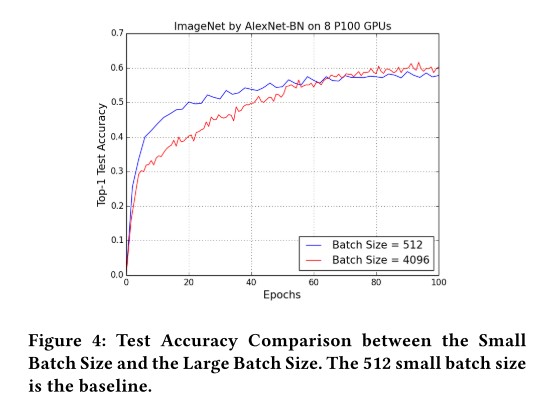
不同batch size 的精度比较:
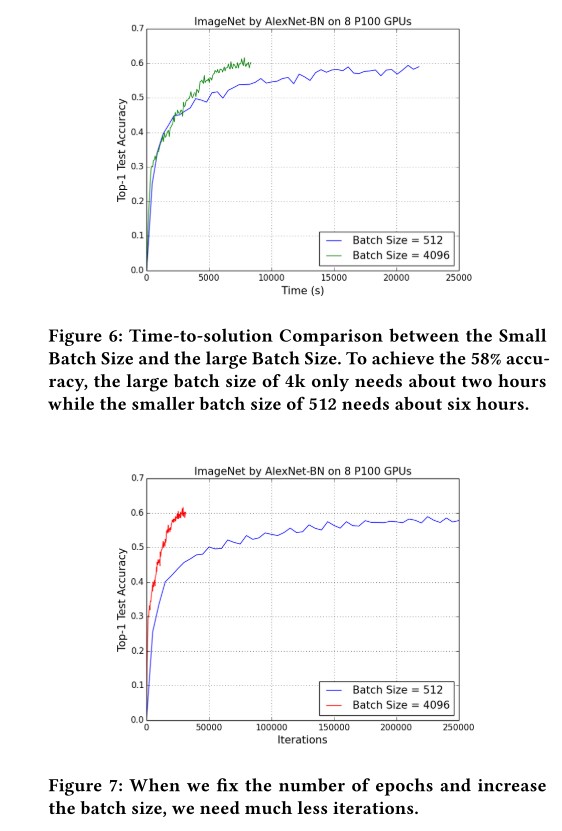
使用large batch可以减少训练时间与迭代次数:
讨论
Large batch 的优点:
- 缩短训练时间。总得计算时间未变,但是通信时间会减少。
- 保持机器的高使用率
将DNN扩展到多机的主要开销:多机之间的通信,Resnet50的scaling ratio是AlexNet的12.5倍,AlexNet要简单一些。
Large batch的挑战
简单使用同步SGD和Large batch会使得测试准确率下降。
矫正准确率降低的方法
- Linear Scaling:学习率同batch size一样线性增长
- Warmup scheme:在前几代中从小学习率逐渐增长到大学习率
思考
- 可否验证LARS方法在其他数据集与其他网络上的性能?从而得到更全面的结果




