Kaggle猫狗识别Pytorch详细搭建过程
文章源码链接,包括Notebook和对应的Pycharm项目。求个Star!!
需求
Kaggle比赛链接 ,给出猫狗图片,然后预测图片中是狗的概率。
训练集有25,000张图片,测试集12,500 张图片。

自己最开始构思大致框架的时候的一个思维导图:
包的导入
需要注意的是将tqdm 改为tqdm.notebook,从而在notebook环境下获得更好的体验。因为导入tqdm的话,会发生进度条打印多次的情况,体验很不好
1 | import os |
相关文件路径配置,在pycharm项目中将相关路径的配置都统一放在config.py中来管理
1 | train_path = 'D:/AIdata/dog vs cat/train' |
数据集的创建
因为Kaggle官方提供的是原始数据,不像之前的手写数字数据集可以从pytorch中直接下载已经处理过的数据集,可以直接将数据放入模型进行训练。因此需要我们自己实现数据集的生成。
数据集生成的总体思路是继承torch.utils.data.Dataset这个类,自己实现getitem和len这两个私有方法来完成对我们自己数据的读取操作。其中getitem这个函数的主要功能是根据样本的索引,返回索引对应的一张图片的图像数据X与对应的标签Y,也就是返回一个对应的训练样本。len这个函数的功能比较简单直接返回数据集中样本的个数即可。
具体而言,getitem的实现思路比较简单,将索引idx转换为图片的路径,然后用PIL的Image包来读取图片数据,然后将数据用torchvision的transforms转换成tensor并且进行Resize来统一大小(给出的图片尺寸不一致)与归一化,这样一来就可以得到图像数据了。因为训练集中图片的文件名上面带有猫狗的标签,所以标签可以通过对图片文件名split后得到然后转成0,1编码。
在获取标签的时候,因为官方提供的测试数据集中并没有猫狗的标签,所以测试集的标签逻辑稍有不同。我的做法是使用一个train标志来进行区分,对于测试的数据,直接将测试样本的标签变成图片自带的id,这样方便后面输出提交的csv文件。因为测试样本不用计算loss,所以将标签置为id是没问题的。
为了实现将idx索引转换成图片路径,需要在init()函数中将所有的图片路径放在一个list中,这可以用os.listdir()来实现,然后就可以根据索引去获得路径了。
需要注意的是,之所以getitem()需要根据索引来返回样本,是因为训练数据并不是一次性将所有样本数据加载到内存中,这样太耗内存。而是只用加载对应batch中的一部分数据,所以通过索引来加载送入模型中的一批数据。
1 | class MyDataset(Dataset): |
测试一下,确保Dataset可以正常迭代
1 | train_ds = MyDataset(train_path) |
输出:
(tensor([[[ 0.5922, 0.6078, 0.6392, ..., 0.9216, 0.8902, 0.8745],
[ 0.5922, 0.6078, 0.6392, ..., 0.9216, 0.8980, 0.8824],
[ 0.5922, 0.6078, 0.6392, ..., 0.9216, 0.9059, 0.8902],
...,
[ 0.2078, 0.2157, 0.2235, ..., -0.9765, -0.9765, -0.9765],
[ 0.2000, 0.2000, 0.2078, ..., -0.9843, -0.9843, -0.9843],
[ 0.1843, 0.1922, 0.2000, ..., -0.9922, -0.9922, -0.9922]],
[[ 0.2863, 0.3020, 0.3333, ..., 0.6000, 0.5843, 0.5686],
[ 0.2863, 0.3020, 0.3333, ..., 0.6000, 0.5922, 0.5765],
[ 0.2863, 0.3020, 0.3333, ..., 0.6000, 0.6000, 0.5843],
...,
[-0.0353, -0.0275, -0.0196, ..., -0.9765, -0.9765, -0.9765],
[-0.0431, -0.0431, -0.0353, ..., -0.9843, -0.9843, -0.9843],
[-0.0588, -0.0510, -0.0431, ..., -0.9922, -0.9922, -0.9922]],
[[-0.3176, -0.3020, -0.2706, ..., -0.0588, -0.0431, -0.0510],
[-0.3176, -0.3020, -0.2706, ..., -0.0510, -0.0431, -0.0431],
[-0.3176, -0.3020, -0.2706, ..., -0.0431, -0.0275, -0.0353],
...,
[-0.5608, -0.5529, -0.5451, ..., -0.9922, -0.9922, -0.9922],
[-0.5686, -0.5686, -0.5608, ..., -1.0000, -1.0000, -1.0000],
[-0.5843, -0.5765, -0.5686, ..., -1.0000, -1.0000, -1.0000]]]), tensor(0))
数据集划分
如前面所述,因为官方测试集没有标签,而且提交结果上去后只有一个log loos来作为分值,没有准确率的结果。所以为了得到准确率这个指标,需要新建个有标签的验证集来查看准确率。
实现思路是使用torch.utils.data.random_split(),来将官方提供训练数据集划分出一部分的验证集。我的比例是80%的训练集,20%的验证集
1 | full_ds = train_ds |
数据加载
我们制作的数据集并不能直接放入模型进行训练,还需要使用一个数据加载器,来加载数据集。使用torch.utils.data.DataLoader()来划分每个batch用来后面训练的时候向网络提供输入数据
1 | train_loader = torch.utils.data.DataLoader(train_ds, batch_size=32, |
1 | new_train_loader = torch.utils.data.DataLoader(new_train_ds, batch_size=32, |
加载过后数据形状从三维变成四维,多的维度是batch_size,这里是32个样本构成一个batch
1 | for i, item in enumerate(train_loader): |
输出:
torch.Size([32, 3, 224, 224])
resize后的图像查看
前面提到过对数据进行了resize和正则化的处理,下面是对处理后的图像的可视化
1 | img_PIL_Tensor = train_ds[1][0] |

网络搭建
网络搭建的框架与之前的手写数字识别的框架一致,两个卷积层后3个全连接层。需要注意的是参数不能套用之前的参数了,因为之前的手写数字的图片很小,而且数据量不大所以尽管参数比较大,也能在我的机子上跑起来(MX150,2GB显存)。猫狗的数据量显然比之前的大,所以需要将参数变小些,才能跑起来。 我实验了下,如果不将网络参数降低的话,只调整batch_size没有用,依然会报显存不足。
1 | import torch.nn.functional as F |
预训练模型
除了自己手动DIY一个网络,也可以使用Pytorch已经提供的一些性能很好的模型比如VGG16,ResNet50等等,然后微调下网络结构,来得到符合自己的任务的网络架构。还可以直接下载这些模型在ImageNet上的预训练参数,然后在自己的数据集上进行训练。
我在这儿选择了ResNet50网络以及预训练好的权重进行了下实验,我在实验室的机器上面用P100跑的,因为自己的笔记本显卡太垃圾了只有2GB显存。
1 | ## 直接设置为True的话下载权重太慢了 |
损失函数和优化函数
1 | net = MyCNN() |
1 |
|
训练日志的打印
在之前的手写数字识别的准确率的计算和画图以日志的打印比较简单,在这更新为topk准确率以及使用tensorboard来画曲线。并且使用tqdm进度条来实时的打印日志。
专门建立一个类来保存和更新准确率的结果,使用类来让代码更加的规范化
1 | class AvgrageMeter(object): |
准确率的计算
torch.topk(input, k, dim=None, largest=True, sorted=True, out=None) -> (Tensor, LongTensor) 返回某一维度前k个的索引
input:一个tensor数据
k:指明是得到前k个数据以及其index
dim: 指定在哪个维度上排序, 默认是最后一个维度
largest:如果为True,按照大到小排序; 如果为False,按照小到大排序
sorted:返回的结果按照顺序返回
out:可缺省,不要
1 | ## topk的准确率计算 |
tensorboard画图
详细的参数讲解参考:https://www.pytorchtutorial.com/pytorch-builtin-tensorboard/
在使用pip install安装tensorboard如果速度很慢经常断线的话可以换个国内的源:pip config set global.index-url https://mirrors.ustc.edu.cn/pypi/web/simple
1 | from torch.utils.tensorboard import SummaryWriter |
画图的结果是实时,还可以放大放小,曲线的平滑度设置等,比自己写的画图函数要方便很多:
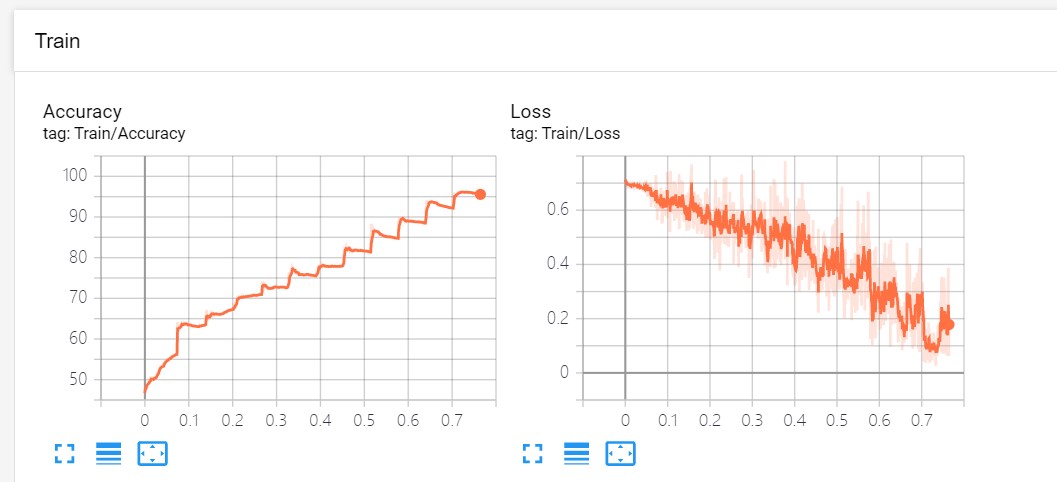
迭代训练
1 | def train( epoch, train_loader, device, model, criterion, optimizer,tensorboard_path): |
模型评估
准确率验证
在验证集上面的验证,求网络的的准确率指标
1 | def validate(validate_loader, device, model, criterion): |
输出测试集的预测结果
将测试集输入进网络,得到测试集的预测结果,并转换成csv文件,用来提交到Kaggle上进行评分。需要注意的是,因为官网要求给的是图片是狗的概率,需要将网络的输出转成概率值。
但实际上测试的时候网络的输出是一正一负的值,不是概率值。这是因为测试的时候没有计算loss ,而softmax这个过程是在计算交叉熵的时候自动计算的,所以在网络架构中最后一层全连接输出后没有softmax计算。因此需要我们手动增加上softmax的过程,这样经过softmax后就可以变成两个概率值了!将图片是狗的概率保存下来,并转成符合官方要求的提交格式。
1 | def submission(csv_path,test_loader, device, model): |
完整调用流程
损失函数和优化方法的确定
1 | net = MyCNN() |
训练过程
需要传入epoch数目,训练数据加载器,设备,网络模型,损失函数,优化方法和tensorboard画图的路径等参数。
注意的是如果使用完整的官方训练数据集来训练网络后,用这个网络去在验证集上面验证是没有意义的,因为验证集的数据是从完整训练数据集上面划分出来,所以相当于在用训练数据验证性能。用划分过后的new_train_loader训练的网络在进行验证才有意义。
1 | # train( 1, train_loader, device,net, criterion, optimizer,tensorboard_path) # 完整的训练数据集 |
输出:
Finished Training
在训练的时候会用tensorboard保存每个时刻的训练数据,需要新打开一个命令端口输入:tensorboard --logdir=/path_to_log_dir/ --port 6006 命令,然后通过在浏览器中输入网址http://localhost:6006/ 来查看
模型的保存和加载
1 | torch.save(net.state_dict(), model_save_path) |
输出:
<All keys matched successfully>
验证过程
输入的网络是上面训练过的网络,或者从模型权重保存路径加载的模型。输出模型在自己划分的验证集上面的准确率,结果是98.84%
1 | validate(validate_loader,device,val_net,criterion) |
输出:
73.56
输出测试集预测结果
1 | submission('./test.csv',test_loader, device, val_net) |
最后在Kaggle上提交预测结果csv文件,得到打分。 需要先报名参赛这些操作,而且只有Dogs vs. Cats Redux: Kernels Edition这个才能够提交数据,最开始的那个6年前的提交通道已经关闭了。提交可以下载Kaggle的API在命令行提交,也可以直接在提交链接提交
结果
文章基于Notebook的过程,也构建了对应的Pycharm项目,将整个过程分模块来编码,架构更清晰。
我总共训练了三个网络,其中MyCNN_net_1使用全部的训练数据,MyCNN_net_2使用划分过的训练数据,RestNet50是预训练的模型,使用完整训练数据训练。
Kaggle上的评分是根据log loss来计算的,分数越低代表模型性能越好。然后其他两个网络使用的完整训练数据集是包含验证集的,所以没有计算验证集的准确率。
| 网络 | epochs | 训练数据 | 得分 | 验证集准确率 |
|---|---|---|---|---|
| ResNet50 | 3 | 完整训练数据集 | 0.06691 | - |
| MyCNN_net_1 | 12 | 划分的80%训练数据集 | 0.73358 | 73.56 |
| MyCNN_net_2 | 12 | 完整训练数据集 | 0.94158 | - |
实验结果并不严谨,只进行了一次,所以存在一些随机性。
其中使用预训练的ResNet50的效果非常好,在猫狗数据集上训练微调的时候loss就很低了,所以只训练了3轮。

问题
自己在搭建网络的时候遇到一个问题就是随便设置的一个网络结构的时候,发现交叉熵的loss会一直维持在0.69,不下降。暂时还没有搞懂问题出在哪儿,后面有时间了研究下,
参考





