范闲写诗器之用LSTM+Pytorch实现自动写诗
LSTM网络经常用于序列预测,因此在NLP领域很常用,本文将利用LSTM网络来搭建一个简单的自动写诗的demo,做这个的时候突然想起庆余年中范闲作诗的片段,所以就把它取名为范闲写诗器,用来供范闲参考哈哈哈。文章的源码放在github上,求个赞!!!
1 | import torch |
相关配置
1 | class DictObj(object): |
唐诗数据查看
唐诗数据文件分为三部分,data部分是唐诗数据的总共包含57580首唐诗数据,其中每一首都被格式化成125个字符,唐诗开始用’
1 | def view_data(poem_path): |
1 | view_data(Config.poem_path) |
1 | (57580, 125) |
可以看到125个字符中,大部分都是空格数据,我统计了下总的数据中将近57%的数据都是空格。如果不去除空格数据的话,模型的虽然最开始训练的时候就有60多的准确率,但是这些准确率是因为预测空格来造成的,所以需要将空格数据给去掉。
构造数据集
这一步的主要工作是将原始的唐诗数据集中的空格给过滤掉,然后根据序列的长度seq_len重新划分无空格的数据集,并得到每个序列的标签。我最开始的时候比较困惑数据的标签应该是什么?纠结的点在于最开始以为上一句诗的标签是不是,下一句诗。比如“床前明月光,”的标签是不是“疑是地上霜”。后面阅读了些资料才搞懂正确的标签应该是这个汉字的下一个汉字,“床前明月光,”对应的标签是“前明月光,疑”。也就是基于字符级的语言模型。
Dive-into-DL-Pytorch 中的例子:
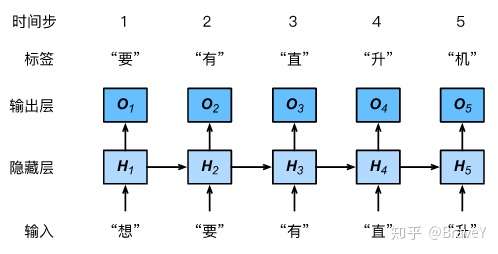
搞懂了标签是什么后,这一步的代码逻辑就好理解了,先从路径文件中得到原始数据poem_data,然后将poem_data中的空格数据给过滤掉并平整到一维得到no_space_data,之后就根据索引去得到对应迭代次数的数据和标签了。
1 | class PoemDataSet(Dataset): |
seq_len 这里我选择的是48,因为考虑到唐诗主要是五言绝句和七言绝句,各自加上一个标点符号也就是6和8,选择一个公约数48,这样刚好凑够8句无言或者6句七言,比较符合唐诗的偶数句对。
1 | poem_ds = PoemDataSet(Config.poem_path, 48) |
1 | poem_ds[0] |
1 | (tensor([8291, 6731, 4770, 1787, 8118, 7577, 7066, 4817, 648, 7121, 1542, 6483, |
1 | poem_loader = DataLoader(poem_ds, |
模型构造
模型使用embedding+LSTM来进行构造,embedding的理解参考 ,Word2Vec和王喆的文章。使用embedding层后将汉字转化为embedding向量,与简单使用One-hot编码可以更好地表示汉字的语义,同时减少特征维度。
向量化后使用LSTM网络来进行训练,LSTM的参数理解可能比较费劲,参考两张图进行理解:
LSTM神经网络输入输出究竟是怎样的? - Scofield的回答 - 知乎中的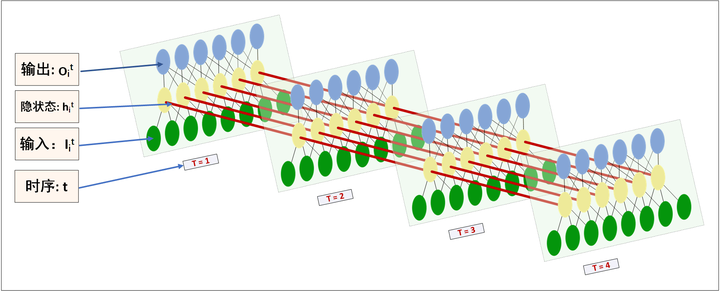
这张图中就能比较好理解input_size=embedding_dim,hidden_dim这两个个参数了。输入的X的维度就是图中绿色节点的数目了,在这里是embedding_dim这个参数就是经过向量化后的每个汉字,hidden_dim就是图中黄色的节点个数了,只不过因为LSTM有h和c两个隐藏状态,所以hidden_dim同时设置了h和c两个隐藏层状态的维度,也就是图中的黄色节点需要乘以2,变成两个的。num_layers的理解参考LSTM细节分析理解(pytorch版) - ymmy的文章 - 知乎的图片就是纵向的深度。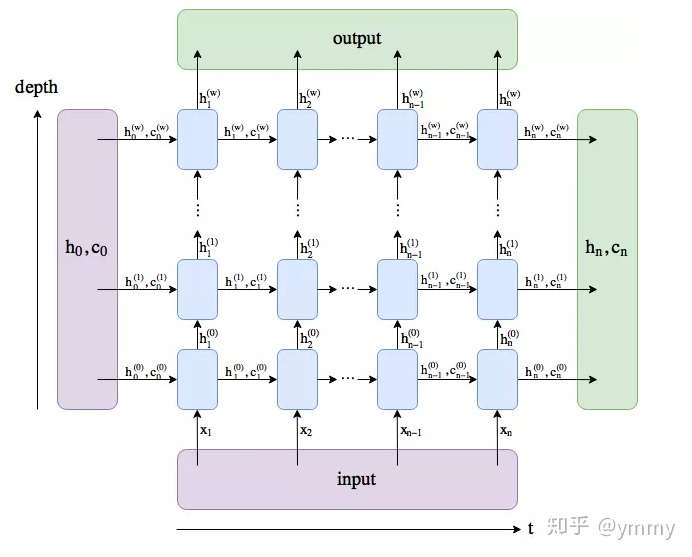
LSTM的深度选择了3层,需要注意的是并不是越深越好,自己的初步实验显示加深到8层的效果并不比3层的效果好,因此选择了3层。
经过LSTM输出的维度也是hidden_dim,使用3层全连接来进一步处理。这里全连接层的激活函数选用的是tanh激活函数,因为初步的对比实验显示,tanh的效果比relu好一些。
1 | # import torch.nn.functional as F |
训练日志的设置
注释参考我之前的文章Kaggle猫狗识别Pytorch详细搭建过程 - BraveY的文章 - 知乎
1 | class AvgrageMeter(object): |
1 | ## topk的准确率计算 |
迭代训练函数
训练中使用tensorboard来绘制曲线,终端输入tensorboard --logdir=/path_to_log_dir/ --port 6006 可查看
1 | def train( epochs, train_loader, device, model, criterion, optimizer,scheduler,tensorboard_path): |
模型初始化
初始化模型,并选择损失函数和优化函数。需要注意的是自己在训练过程中发现会发生loss上升的情况,这是因为到后面lr学习率过大导致的,解决的办法是是使用学习率动态调整。这里选择了步长调整的方法,每过10个epoch,学习率调整为原来的0.1。pytorch还有许多其他调整方法,参考这篇文章
初始学习率设置为0.001,稍微大点变成0.01最开始的训练效果都比较差,loss直接上百,不下降。
1 | # 上述参数的配置网络训练显存消耗为2395M,超过显存的话,重新调整下网络配置 |
1 | model |
1 | MyPoetryModel_tanh( |
训练
1 | # model.load_state_dict(torch.load(Config.model_save_path)) # 模型加载、 |
1 | <All keys matched successfully> |
1 | #因为使用tensorboard画图会产生很多日志文件,这里进行清空操作 |
1 | train(epochs, poem_loader, device, model, criterion, optimizer,scheduler, Config.tensorboard_path) |
1 | #模型保存 |
模型使用
使用训练好的模型来进行自动写诗创作,模型训练了30多个epoch,’train_loss’: ‘0.452125’, ‘train_acc’: ‘91.745990’
1 | model.load_state_dict(torch.load(Config.model_save_path)) # 模型加载 |
1 | <All keys matched successfully> |
生成的逻辑是输入一个汉字之后,给出对应的预测输出,如果这个输出所在的范围在给定的句子中,就摒弃这个输出,并用给定句子的下一个字做为输入,
直到输出的汉字超过给定的句子范围,用预测的输出句子作为下一个输入。
因为每次模型输出的还包括h和c两个隐藏状态,所以前面的输入都会更新隐藏状态,来影响当前的输出。也就是hidden这个tensor是一直在模型中传递,只要没有结束
1 | def generate(model, start_words, ix2word, word2ix,device): |
1 | results = generate(model,'雨', ix2word,word2ix,device) |
1 | 雨 余 芳 草 净 沙 尘 , 水 绿 滩 平 一 带 春 。 唯 有 啼 鹃 似 留 客 , 桃 花 深 处 更 无 人 。 |
1 | results = generate(model,'湖光秋月两相得', ix2word,word2ix,device) |
1 | 湖 光 秋 月 两 相 得 , 楚 调 抖 纹 难 自 干 。 唱 至 公 来 尊 意 敬 , 为 君 急 唱 曲 江 清 。 |
1 | results = generate(model,'人生得意须尽欢,', ix2word,word2ix,device) |
1 | 人 生 得 意 须 尽 欢 , 吾 见 古 人 未 能 休 。 空 令 月 镜 终 坐 我 , 梦 去 十 年 前 几 回 。 谁 谓 一 朝 天 不 极 , 重 阳 堪 发 白 髭 肥 。 |
1 | results = generate(model,'万里悲秋常作客,', ix2word,word2ix,device) |
1 | 万 里 悲 秋 常 作 客 , 伤 人 他 日 识 文 诚 。 经 时 偏 忆 诸 公 处 , 一 叶 黄 花 未 有 情 。 |
1 | results = generate(model,'风急天高猿啸哀,渚清沙白鸟飞回。', ix2word,word2ix,device) |
1 | 风 急 天 高 猿 啸 哀 , 渚 清 沙 白 鸟 飞 回 。 孤 吟 一 片 秋 云 起 , 漏 起 傍 天 白 雨 来 。 |
1 | results = generate(model,'千山鸟飞绝,万径人踪灭。', ix2word,word2ix,device) |
1 | 千 山 鸟 飞 绝 , 万 径 人 踪 灭 。 日 暮 沙 外 亭 , 自 思 林 下 客 。 |
参考
Dive-into-DL-Pytorch RNN章节







