项目的github地址 包括notebook和python文件以及训练、验证、测试数据,预训练权重较大,上传到了百度网盘链接:https://pan.baidu.com/s/1mLcPTgb2m5HPgkT3XcGVCg 提取码:n41n
包的导入 与以前的相比,主要增加了简繁转换的包zhconv,变长序列处理的pad_sequence, pack_padded_sequence, pad_packed_sequence等
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 import torchimport osimport randomimport re import gensim import jieba from torch import nn import numpy as np from torch.utils.data import Dataset,DataLoaderimport torch.optim as optimfrom torch.utils.tensorboard import SummaryWriter from tqdm.notebook import tqdmfrom zhconv import convert from torch.nn.utils.rnn import pad_sequence,pack_padded_sequence,pad_packed_sequence
参数配置 这里为了使用预训练的中文维基词向量,必须将embedding层的维度设置为50维以和预训练权重匹配,其他的参数如dropout 概率,层数等都可以自定以
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 class DictObj (object def __init__ (self, mp ): self.map = mp def __setattr__ (self, name, value ): if name == 'map' : object .__setattr__(self, name, value) return self.map [name] = value def __getattr__ (self, name ): return self.map [name] Config = DictObj({ 'train_path' : "D:/AIdata/Sentiment-classification/Dataset/train.txt" , 'test_path' : "D:/AIdata/Sentiment-classification/Dataset/test.txt" , 'validation_path' : "D:/AIdata/Sentiment-classification/Dataset/validation.txt" , 'pred_word2vec_path' :'D:/AIdata/Sentiment-classification/Dataset/wiki_word2vec_50.bin' , 'tensorboard_path' :'./tensorboard' , 'model_save_path' :'./modelDict/model.pth' , 'embedding_dim' :50 , 'hidden_dim' :100 , 'lr' :0.001 , 'LSTM_layers' :3 , 'drop_prob' : 0.5 , 'seed' :0 })
数据集构建 词汇表建立 首先建立训练数据的词汇表,实现汉字转索引。构建词汇表的逻辑:首先读取训练集的数据,然后使用zhconv包统一转换成简体,
这里思路比较简单,但是有个坑,导致我调了一天的bug。就是每次set操作后对应的顺序是不同的,因为我没有将词汇表保存下来,想的是每次程序运行的时候再来重新构建,因此每次重新set之后得到的词汇表也是不一致的,导致同样的语言文本经过不同的词汇表转换后,每次都得到不同的输入,
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 def build_word_dict (train_path ): words = [] max_len = 0 total_len = 0 with open (train_path,'r' ,encoding='UTF-8' ) as f: lines = f.readlines() for line in lines: line = convert(line, 'zh-cn' ) line_words = re.split(r'[\s]' , line)[1 :-1 ] max_len = max (max_len, len (line_words)) total_len += len (line_words) for w in line_words: words.append(w) words = list (set (words)) words = sorted (words) word2ix = {w:i+1 for i,w in enumerate (words)} ix2word = {i+1 :w for i,w in enumerate (words)} word2ix['<unk>' ] = 0 ix2word[0 ] = '<unk>' avg_len = total_len / len (lines) return word2ix, ix2word, max_len, avg_len
1 word2ix, ix2word, max_len, avg_len = build_word_dict(Config.train_path)
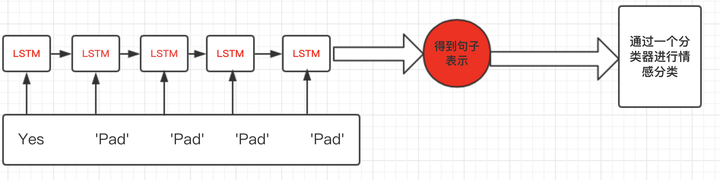
数据变长处理 输入样本的中,词汇的长度不一致,最大的长度有679个词,平均而言只有44个词,所以如果只是单纯的填0来进行维度统一的话,大量的0填充会让模型产生误差,忆臻文章 中的图片:
为了处理这种情况需要将序列长度不一致的样本,根据长度排序后进行按照批次来分别填充,详细介绍参考尹相楠的文章 和腾仔的文章 , 在这不赘述。
1 2 3 4 5 6 7 8 9 10 11 12 def mycollate_fn (data ): data.sort(key=lambda x: len (x[0 ]), reverse=True ) data_length = [len (sq[0 ]) for sq in data] input_data = [] label_data = [] for i in data: input_data.append(i[0 ]) label_data.append(i[1 ]) input_data = pad_sequence(input_data, batch_first=True , padding_value=0 ) label_data = torch.tensor(label_data) return input_data, label_data, data_length
数据集的类里面主要是获取数据和标签,稍微需要注意的是考虑到测试集和验证集中一些不会在训练语料库中出现的词汇,需要将这些词汇置为0,来避免索引错误
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 class CommentDataSet (Dataset ): def __init__ (self, data_path, word2ix, ix2word ): self.data_path = data_path self.word2ix = word2ix self.ix2word = ix2word self.data, self.label = self.get_data_label() def __getitem__ (self, idx: int ): return self.data[idx], self.label[idx] def __len__ (self ): return len (self.data) def get_data_label (self ): data = [] label = [] with open (self.data_path, 'r' , encoding='UTF-8' ) as f: lines = f.readlines() for line in lines: try : label.append(torch.tensor(int (line[0 ]), dtype=torch.int64)) except BaseException: print('not expected line:' + line) continue line = convert(line, 'zh-cn' ) line_words = re.split(r'[\s]' , line)[1 :-1 ] words_to_idx = [] for w in line_words: try : index = self.word2ix[w] except BaseException: index = 0 words_to_idx.append(index) data.append(torch.tensor(words_to_idx, dtype=torch.int64)) return data, label
训练集,验证集,测试集,加载 1 2 3 4 5 6 7 8 9 10 11 train_data = CommentDataSet(Config.train_path, word2ix, ix2word) train_loader = DataLoader(train_data, batch_size=16 , shuffle=True , num_workers=0 , collate_fn=mycollate_fn,) validation_data = CommentDataSet(Config.validation_path, word2ix, ix2word) validation_loader = DataLoader(validation_data, batch_size=16 , shuffle=True , num_workers=0 , collate_fn=mycollate_fn,) test_data = CommentDataSet(Config.test_path, word2ix, ix2word) test_loader = DataLoader(test_data, batch_size=16 , shuffle=False , num_workers=0 , collate_fn=mycollate_fn,)
1 2 3 not expected line: not expected line:
预训练权重加载 这里需要将预训练的中文word2vec的权重初始到pytorch embedding层,主要的逻辑思路首先使用gensim包来加载权重,然后根据前面建立的词汇表,初始一个vocab_size*embedding_dim的0矩阵weight,之后对每个词汇查询是否在预训练的word2vec中有权重,如果有的话就将这个权重复制到weight中,最后使用weight来初始embedding层就可以了。
1 2 word2vec_model = gensim.models.KeyedVectors.load_word2vec_format(Config.pred_word2vec_path, binary=True )
1 2 word2vec_model.__dict__['vectors' ].shape
1 2 3 4 5 6 7 8 9 10 11 def pre_weight (vocab_size ): weight = torch.zeros(vocab_size,Config.embedding_dim) for i in range (len (word2vec_model.index2word)): try : index = word2ix[word2vec_model.index2word[i]] except : continue weight[index, :] = torch.from_numpy(word2vec_model.get_vector( ix2word[word2ix[word2vec_model.index2word[i]]])) return weight
模型构建 模型的构建与前面的LSTM自动写诗 大体一致,即embedding后LSTM层然后3层全连接,激活函数选择了tanh。不同的点在于,这里的输出只保留时间步的最后一步,用来当作预测结果。也就是最后一个全连接层的输出取最后一个时间步的输出。以及为了防止过拟合而采用了Dropout。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 class SentimentModel (nn.Module ): def __init__ (self, embedding_dim, hidden_dim,pre_weight ): super (SentimentModel, self).__init__() self.hidden_dim = hidden_dim self.embeddings = nn.Embedding.from_pretrained(pre_weight) self.embeddings.weight.requires_grad = True self.lstm = nn.LSTM(embedding_dim, self.hidden_dim, num_layers=Config.LSTM_layers, batch_first=True , dropout=Config.drop_prob, bidirectional=False ) self.dropout = nn.Dropout(Config.drop_prob) self.fc1 = nn.Linear(self.hidden_dim,256 ) self.fc2 = nn.Linear(256 ,32 ) self.fc3 = nn.Linear(32 ,2 ) def forward (self, input , batch_seq_len, hidden=None ): embeds = self.embeddings(input ) embeds = pack_padded_sequence(embeds,batch_seq_len, batch_first=True ) batch_size, seq_len = input .size() if hidden is None : h_0 = input .data.new(Config.LSTM_layers*1 , batch_size, self.hidden_dim).fill_(0 ).float () c_0 = input .data.new(Config.LSTM_layers*1 , batch_size, self.hidden_dim).fill_(0 ).float () else : h_0, c_0 = hidden output, hidden = self.lstm(embeds, (h_0, c_0)) output,_ = pad_packed_sequence(output,batch_first=True ) output = self.dropout(torch.tanh(self.fc1(output))) output = torch.tanh(self.fc2(output)) output = self.fc3(output) last_outputs = self.get_last_output(output, batch_seq_len) return last_outputs,hidden def get_last_output (self,output,batch_seq_len ): last_outputs = torch.zeros((output.shape[0 ],output.shape[2 ])) for i in range (len (batch_seq_len)): last_outputs[i] = output[i][batch_seq_len[i]-1 ] last_outputs = last_outputs.to(output.device) return last_outputs
准确率指标 分别有两个指标一个是topk的AverageMeter,另一个是使用混淆矩阵。混淆矩阵的实现的时候先转为(pred, label)的二元对,然后相应的填充到表中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 class AvgrageMeter (object def __init__ (self ): self.reset() def reset (self ): self.avg = 0 self.sum = 0 self.cnt = 0 def update (self, val, n=1 ): self.sum += val * n self.cnt += n self.avg = self.sum / self.cnt
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 class ConfuseMeter (object def __init__ (self ): self.reset() def reset (self ): self.confuse_mat = torch.zeros(2 ,2 ) self.tp = self.confuse_mat[0 ,0 ] self.fp = self.confuse_mat[0 ,1 ] self.tn = self.confuse_mat[1 ,1 ] self.fn = self.confuse_mat[1 ,0 ] self.acc = 0 self.pre = 0 self.rec = 0 self.F1 = 0 def update (self, output, label ): pred = output.argmax(dim = 1 ) for l, p in zip (label.view(-1 ),pred.view(-1 )): self.confuse_mat[p.long(), l.long()] += 1 self.tp = self.confuse_mat[0 ,0 ] self.fp = self.confuse_mat[0 ,1 ] self.tn = self.confuse_mat[1 ,1 ] self.fn = self.confuse_mat[1 ,0 ] self.acc = (self.tp+self.tn) / self.confuse_mat.sum () self.pre = self.tp / (self.tp + self.fp) self.rec = self.tp / (self.tp + self.fn) self.F1 = 2 * self.pre*self.rec / (self.pre + self.rec)
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 def accuracy (output, label, topk=(1 , ): maxk = max (topk) batch_size = label.size(0 ) _, pred = output.topk(maxk, 1 , True , True ) pred = pred.t() correct = pred.eq(label.view(1 , -1 ).expand_as(pred)) rtn = [] for k in topk: correct_k = correct[:k].view(-1 ).float ().sum (0 ) rtn.append(correct_k.mul_(100.0 / batch_size)) return rtn
训练函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 def train (epoch,epochs, train_loader, device, model, criterion, optimizer,scheduler,tensorboard_path ): model.train() top1 = AvgrageMeter() model = model.to(device) train_loss = 0.0 for i, data in enumerate (train_loader, 0 ): inputs, labels, batch_seq_len = data[0 ].to(device), data[1 ].to(device), data[2 ] optimizer.zero_grad() outputs,hidden = model(inputs,batch_seq_len) loss = criterion(outputs,labels) loss.backward() optimizer.step() _,pred = outputs.topk(1 ) prec1, prec2= accuracy(outputs, labels, topk=(1 ,2 )) n = inputs.size(0 ) top1.update(prec1.item(), n) train_loss += loss.item() postfix = {'train_loss' : '%.6f' % (train_loss / (i + 1 )), 'train_acc' : '%.6f' % top1.avg} train_loader.set_postfix(log=postfix) if os.path.exists(tensorboard_path) == False : os.mkdir(tensorboard_path) writer = SummaryWriter(tensorboard_path) writer.add_scalar('Train/Loss' , loss.item(), epoch) writer.add_scalar('Train/Accuracy' , top1.avg, epoch) writer.flush() scheduler.step()
验证函数 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 def validate (epoch,validate_loader, device, model, criterion, tensorboard_path ): val_acc = 0.0 model = model.to(device) model.eval () with torch.no_grad(): val_top1 = AvgrageMeter() validate_loader = tqdm(validate_loader) validate_loss = 0.0 for i, data in enumerate (validate_loader, 0 ): inputs, labels, batch_seq_len = data[0 ].to(device), data[1 ].to(device), data[2 ] outputs,_ = model(inputs, batch_seq_len) loss = criterion(outputs, labels) prec1, prec2 = accuracy(outputs, labels, topk=(1 , 2 )) n = inputs.size(0 ) val_top1.update(prec1.item(), n) validate_loss += loss.item() postfix = {'validate_loss' : '%.6f' % (validate_loss / (i + 1 )), 'validate_acc' : '%.6f' % val_top1.avg} validate_loader.set_postfix(log=postfix) if os.path.exists(tensorboard_path) == False : os.mkdir(tensorboard_path) writer = SummaryWriter(tensorboard_path) writer.add_scalar('Validate/Loss' , loss.item(), epoch) writer.add_scalar('Validate/Accuracy' , val_top1.avg, epoch) writer.flush() val_acc = val_top1.avg return val_acc
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 def test (validate_loader, device, model, criterion ): val_acc = 0.0 model = model.to(device) model.eval () confuse_meter = ConfuseMeter() with torch.no_grad(): val_top1 = AvgrageMeter() validate_loader = tqdm(validate_loader) validate_loss = 0.0 for i, data in enumerate (validate_loader, 0 ): inputs, labels, batch_seq_len = data[0 ].to(device), data[1 ].to(device), data[2 ] outputs,_ = model(inputs, batch_seq_len) prec1, prec2 = accuracy(outputs, labels, topk=(1 , 2 )) n = inputs.size(0 ) val_top1.update(prec1.item(), n) confuse_meter.update(outputs, labels) postfix = { 'test_acc' : '%.6f' % val_top1.avg, 'confuse_acc' : '%.6f' % confuse_meter.acc} validate_loader.set_postfix(log=postfix) val_acc = val_top1.avg return confuse_meter
随机数种子设置 随机种子的设置需要在模型初始之前,这样才能保证模型每次初始化的时候得到的是一样的权重,从而保证能够复现每次训练结果torch.backends.cudnn.benchmark = True 参考 https://zhuanlan.zhihu.com/p/73711222
1 2 3 4 5 6 7 8 9 def set_seed (seed ): np.random.seed(seed) random.seed(seed) torch.manual_seed(seed) if torch.cuda.is_available(): torch.cuda.manual_seed_all(seed) torch.backends.cudnn.deterministic = True
模型初始化 1 2 3 4 5 6 7 8 model = SentimentModel(embedding_dim=Config.embedding_dim, hidden_dim=Config.hidden_dim, pre_weight=pre_weight(len (word2ix))) device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu" ) epochs = 3 optimizer = optim.Adam(model.parameters(), lr=Config.lr) scheduler = torch.optim.lr_scheduler.StepLR(optimizer, step_size = 10 ,gamma=0.1 ) criterion = nn.CrossEntropyLoss()
1 2 3 4 5 6 7 8 SentimentModel( (embeddings): Embedding(51406, 50) (lstm): LSTM(50, 100, num_layers=3, batch_first=True, dropout=0.5) (dropout): Dropout(p=0.5, inplace=False) (fc1): Linear(in_features=100, out_features=256, bias=True) (fc2): Linear(in_features=256, out_features=32, bias=True) (fc3): Linear(in_features=32, out_features=2, bias=True) )
迭代训练 在每个epoch中同时收集验证集准确率,防止过拟合
1 2 3 4 5 import shutil if os.path.exists(Config.tensorboard_path): shutil.rmtree(Config.tensorboard_path) os.mkdir(Config.tensorboard_path)
训练时win10+Pytorch1.3会出现随机的bug,RuntimeError: cuda runtime error (719) : unspecified launch failure at C:/w/1/s/tmp_conda_3.6_081743/conda/conda-bld/pytorch_1572941935551/work/aten/src\THC/generic/THCTensorMath.cu:26 官方还没有解决 需要重启kernel/或者系统
1 2 3 4 5 for epoch in range (epochs): train_loader = tqdm(train_loader) train_loader.set_description('[%s%04d/%04d %s%f]' % ('Epoch:' , epoch + 1 , epochs, 'lr:' , scheduler.get_lr()[0 ])) train(epoch, epochs, train_loader, device, model, criterion, optimizer,scheduler, Config.tensorboard_path) validate(epoch, validation_loader,device,model,criterion,Config.tensorboard_path)
训练3个epoch后训练集准确率: ‘train_acc’: ‘92.499250’ ,验证集准确率:’validate_acc’: ‘82.376976’
1 2 3 4 if os.path.exists(Config.model_save_path) == False : os.mkdir('./modelDict/' ) torch.save(model.state_dict(), Config.model_save_path)
测试集相关指标 包括精确率,召回率,F1Score以及混淆矩阵,测试集准确率达到85%,精确率88%,召回率80.7%,F1分数:0.84
1 2 3 4 5 6 model_test = SentimentModel(embedding_dim=Config.embedding_dim, hidden_dim=Config.hidden_dim, pre_weight=pre_weight(len (word2ix))) optimizer_test = optim.Adam(model_test.parameters(), lr=Config.lr) scheduler_test = torch.optim.lr_scheduler.StepLR(optimizer, step_size = 10 ,gamma=0.1 ) criterion_test = nn.CrossEntropyLoss()
1 model_test.load_state_dict(torch.load(Config.model_save_path),strict=True )
1 <All keys matched successfully>
1 2 confuse_meter = ConfuseMeter() confuse_meter = test(test_loader,device,model_test,criterion_test)
1 print('prec:%.6f recall:%.6f F1:%.6f' %(confuse_meter.pre,confuse_meter.rec, confuse_meter.F1))
1 prec:0.880240 recall:0.807692 F1:0.842407
1 2 confuse_meter.confuse_mat
1 2 tensor([[147., 20.], [ 35., 167.]])
模型使用 使用模型来对自己收集的豆瓣上面对《龙岭迷窟》的评论进行分类预测。第一条是好评,第二条是差评,使用自己的模型能够正确对两条评论进行分类。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 def predict (comment_str, model, device ): model = model.to(device) seg_list = jieba.lcut(comment_str,cut_all=False ) words_to_idx = [] for w in seg_list: try : index = word2ix[w] except : index = 0 words_to_idx.append(index) inputs = torch.tensor(words_to_idx).to(device) inputs = inputs.reshape(1 ,len (inputs)) outputs,_ = model(inputs, [len (inputs),]) pred = outputs.argmax(1 ).item() return pred
1 comment_str1 = "这一部导演、监制、男一都和《怒晴湘西》都是原班人马,这次是黄土高原上《龙岭密窟》的探险故事,有蝙蝠群、巨型蜘蛛这些让人瑟瑟发抖的元素,紧张刺激的剧情挺期待的。潘老师演技一如既往地稳。本来对姜超的印象也还在李大嘴这个喜剧角色里,居然没让人失望,还挺贴合王胖子这个角色。"
1 2 3 4 if (predict(comment_str1,model,device)): print("Negative" ) else : print("Positive" )
1 comment_str2 = "年代感太差,剧情非常的拖沓,还是冗余情节的拖沓。特效五毛,实在是太烂。潘粤明对这剧也太不上心了,胖得都能演王胖子了,好歹也锻炼一下。烂剧!"
1 2 3 4 if (predict(comment_str2,model,device)): print("Negative" ) else : print("Positive" )
参考 https://blog.csdn.net/nlpuser/article/details/83627709
https://zhuanlan.zhihu.com/p/70822702
https://zhuanlan.zhihu.com/p/59772104